
Introduction to Disk Structure
Disk structure is a fundamental concept in computer science and operating systems, dealing with how data is organized, stored, and accessed on a disk. This includes understanding the physical and logical layout of disks, file systems, and the way data is read and written.
Overview of Disk Structure
1. Physical Disk Structure
- Platters: Disks consist of platters, which are flat, circular disks coated with magnetic material. Data is stored magnetically on these platters.
- Tracks: Each platter is divided into concentric circles called tracks. Tracks are numbered, starting from zero at the outer edge.
- Sectors: Tracks are further divided into smaller units called sectors, which are the smallest storage unit on a disk. Each sector typically stores 512 bytes or 4096 bytes of data.
- Cylinders: A cylinder is a collection of tracks located at the same position on each platter. All tracks in a cylinder can be read without moving the disk’s read/write head vertically.
2. Logical Disk Structure
- Clusters: A cluster, also known as an allocation unit, is a group of one or more sectors and is the smallest unit of disk space allocation for a file. File systems manage space in terms of clusters rather than sectors.
- Partitions: Disks can be divided into partitions, each of which functions as a separate disk drive. Partitions can have different file systems and serve different purposes (e.g., boot, data, recovery).
- File Systems: The file system manages how data is stored and retrieved on a disk. Common file systems include FAT32, NTFS, ext3, ext4, etc.
Disk Access and Management
1. Disk Scheduling Algorithms
- FCFS (First-Come, First-Served): Requests are processed in the order they arrive. Simple but not always efficient.
- SSTF (Shortest Seek Time First): The disk head moves to the request closest to its current position, reducing seek time but possibly causing starvation.
- SCAN (Elevator Algorithm): The disk head moves in one direction fulfilling requests until it reaches the end, then reverses direction.
- C-SCAN (Circular SCAN): Similar to SCAN, but the head returns to the beginning once it reaches the end, ensuring more uniform wait times.
- LOOK and C-LOOK: Variants of SCAN and C-SCAN that only go as far as the last request in each direction, rather than to the disk’s physical ends.
2. Disk Formatting
- Low-Level Formatting: Involves creating the physical tracks and sectors on the disk. It’s usually done by the manufacturer.
- Partitioning: Dividing the disk into logical sections (partitions) for organizing data. Each partition can be formatted with a specific file system.
- High-Level Formatting: Involves creating a file system on a partition, setting up the necessary structures (like the file allocation table or inode tables) for managing files and directories.
Disk Performance
1. Seek Time: The time it takes for the disk head to move to the track where data is stored. Lower seek times improve performance.
2. Rotational Latency: The delay waiting for the disk to rotate to the correct sector under the read/write head. It depends on the rotational speed of the disk.
3. Data Transfer Rate: The speed at which data is transferred between the disk and memory. It is affected by both the hardware (disk speed, interface) and software (file system efficiency).
Advantages and Disadvantages
Advantages
- Cost-Effective: Hard disk drives (HDDs) offer a large amount of storage at a lower cost compared to SSDs.
- Non-Volatile Storage: Data is retained even when the power is off, making it suitable for long-term storage.
- High Capacity: HDDs can store a vast amount of data, suitable for applications requiring large storage space.
Disadvantages
- Slower Access Speed: Compared to SSDs, HDDs have slower data access times due to mechanical parts.
- Mechanical Failure: Moving parts are subject to wear and tear, which can lead to mechanical failures.
- Noise and Heat: The mechanical operation of HDDs generates noise and heat, which can affect system performance and reliability.
Conclusion
Understanding disk structure is essential for optimizing data storage and retrieval, managing file systems, and improving overall system performance. It also informs decisions regarding storage solutions based on specific needs and constraints.
Disk Performance Parameters
Disk performance parameters are critical metrics used to evaluate the efficiency and speed of a storage device, particularly hard disk drives (HDDs) and solid-state drives (SSDs). These parameters determine how quickly and efficiently data can be read from or written to a disk. Understanding these parameters can help in selecting the right storage solution and optimizing system performance.
Key Disk Performance Parameters
1. Seek Time
- Definition: Seek time is the time it takes for the disk drive’s read/write head to move to the track where the data is stored.
- Components:
- Average Seek Time: The average time for the head to move between tracks.
- Track-to-Track Seek Time: The time it takes to move the head to an adjacent track.
- Impact: Lower seek times result in faster data access and improved performance, especially for applications that require frequent access to small files scattered across the disk.
2. Rotational Latency
- Definition: Rotational latency is the delay waiting for the desired disk sector to rotate under the read/write head.
- Calculation: It depends on the rotational speed of the disk, measured in revolutions per minute (RPM). The formula is: Rotational Latency=60RPM×2 seconds per revolution\text{Rotational Latency} = \frac{60}{\text{RPM} \times 2} \text{ seconds per revolution}Rotational Latency=RPM×260 seconds per revolution
- Impact: Lower rotational latency means faster access to data. HDDs with higher RPM have lower latency but may consume more power and generate more heat.
3. Data Transfer Rate
- Definition: The speed at which data is transferred between the disk and the computer’s memory.
- Types:
- Internal Data Transfer Rate: The rate at which data moves within the disk itself.
- External Data Transfer Rate: The rate at which data is transferred from the disk to the host system.
- Units: Measured in megabytes per second (MB/s) or gigabytes per second (GB/s).
- Impact: Higher data transfer rates lead to quicker data reads and writes, which is crucial for high-performance applications and large file transfers.
4. Throughput
- Definition: The amount of data processed by the disk in a given time period.
- Measurement: Throughput is often expressed in megabytes per second (MB/s).
- Factors Affecting Throughput:
- Workload Type: Sequential vs. random read/write operations.
- Queue Depth: The number of outstanding requests waiting to be processed.
- Impact: Higher throughput means the disk can handle more data in less time, beneficial for applications with high data demands.
5. Input/Output Operations Per Second (IOPS)
- Definition: IOPS is a measure of how many read or write operations a disk can perform in one second.
- Measurement: Indicates the disk’s ability to handle random access workloads.
- Impact: Higher IOPS are critical for databases, virtual machines, and other I/O-intensive applications.
6. Cache Size
- Definition: The amount of temporary storage on the disk used to hold frequently accessed data.
- Impact: A larger cache can improve performance by reducing the need to access slower disk storage for frequently used data.
7. Access Time
- Definition: Access time is the sum of seek time, rotational latency, and command processing time.
- Impact: Lower access times result in faster data retrieval, which is crucial for applications requiring rapid data access.
8. Response Time
- Definition: The total time taken to complete a read or write operation, including the time to process commands and transfer data.
- Impact: Faster response times improve the performance of interactive applications where users are waiting for data to load.
Conclusion
Understanding disk performance parameters is crucial for selecting the appropriate storage solutions and optimizing system performance. By analyzing these metrics, you can make informed decisions about hardware upgrades, system configurations, and workload management to achieve the desired balance between speed, capacity, and cost.
Disk scheduling policies
Disk scheduling is a technique used by operating systems to manage the order in which disk I/O (input/output) requests are processed. Also known as I/O scheduling, the main goals of disk scheduling are to optimize the performance of disk operations, reduce data access times, and improve overall system efficiency.
In this article, we will explore different types of disk scheduling algorithms and their functions. By understanding and implementing these algorithms, we can optimize system performance and ensure faster data retrieval.
What are Disk Scheduling Algorithms?
Disk scheduling algorithms are crucial for managing how data is read from and written to a computer’s hard disk. These algorithms determine the order in which disk read and write requests are processed, significantly impacting the speed and efficiency of data access. Common disk scheduling methods include:
- First-Come, First-Served (FCFS)
- Shortest Seek Time First (SSTF)
- SCAN
- C-SCAN
1. First-Come, First-Served (FCFS)
Description:
- FCFS processes disk I/O requests in the exact order they arrive, without reordering them.
- The disk head services requests sequentially as they are received, moving from one request to the next in the queue.
Advantages:
- Simplicity: FCFS is straightforward to implement and understand. It ensures that requests are handled in the order they are requested.
- Fairness: Every request is treated equally, so there is no risk of starvation or indefinite postponement.
Disadvantages:
- Inefficiency: If a large request is followed by smaller ones, the small requests may experience long waiting times. This is known as the “convoy effect.”
- High Seek Time: The disk head may move extensively if requests are scattered across the disk, leading to inefficient use of the disk.
Example:
Initial Setup
- Current Position of the Read/Write Head: 50
- Order of Requests: (82, 170, 43, 140, 24, 16, 190)
FCFS Processing Steps
1. Current Position: 50
2. Request Order:**
- Move from 50 to 82:
- Seek Time: |82 – 50| = 32 tracks
- Move from 82 to 170:
- Seek Time: |170 – 82| = 88 tracks
- Move from 170 to 43:
- Seek Time: |43 – 170| = 127 tracks
- Move from 43 to 140:
- Seek Time: |140 – 43| = 97 tracks
- Move from 140 to 24:
- Seek Time: |24 – 140| = 116 tracks
- Move from 24 to 16:
- Seek Time: |16 – 24| = 8 tracks
- Move from 16 to 190:
- Seek Time: |190 – 16| = 174 tracks
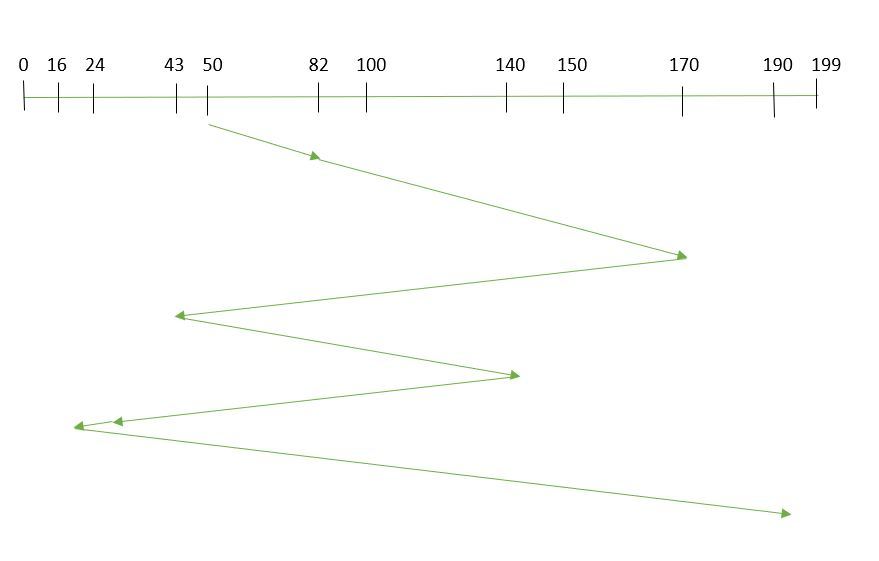
Total Seek Time Calculation
Now, we calculate the total seek time by summing up the seek times for each move:Total Seek Time=32+88+127+97+116+8+174=642 tracks\text{Total Seek Time} = 32 + 88 + 127 + 97 + 116 + 8 + 174 = 642 \text{ tracks}Total Seek Time=32+88+127+97+116+8+174=642 tracks
FCFS Sequence
Here’s the sequence in which the read/write head will move:
- Start: 50
- Move to: 82
- Move to: 170
- Move to: 43
- Move to: 140
- Move to: 24
- Move to: 16
- Move to: 190
Conclusion
The FCFS policy processes requests in the exact order they arrive, which can lead to inefficient use of the disk and increased seek times when requests are spread unevenly across the disk. This example highlights how the head moves in a non-optimized fashion, resulting in a high total seek time of 642 tracks.
2. Shortest Seek Time First (SSTF)
Description: In the Shortest Seek Time First (SSTF) algorithm, the disk scheduler selects the request with the shortest seek time from the current head position. This means that the disk head will move to the request that is closest to its current position before moving to other requests. SSTF aims to minimize the average seek time by processing requests that require the least movement first.
How It Works:
- Calculate Seek Times: The seek time for each request in the queue is calculated based on the distance between the current head position and each request’s track.
- Select Shortest Seek Time: The request with the shortest seek time is chosen for servicing.
- Update Position: After servicing the chosen request, the head position is updated to the track of that request, and the seek time calculation is repeated for the remaining requests.
Advantages:
- Reduced Average Seek Time: By always choosing the closest request, SSTF typically results in a lower average seek time compared to FCFS.
- Increased Throughput: More efficient head movement can lead to increased throughput as the disk can handle more requests in a given period.
Disadvantages:
- Starvation: Requests that are far from the current head position might suffer from starvation if new requests keep arriving closer to the head.
- Complexity: SSTF requires constant recalculation of seek times and may be more complex to implement than FCFS.
Example:
Initial Setup
- Current Position of the Read/Write Head: 50
- Order of Requests: (82, 170, 43, 140, 24, 16, 190)
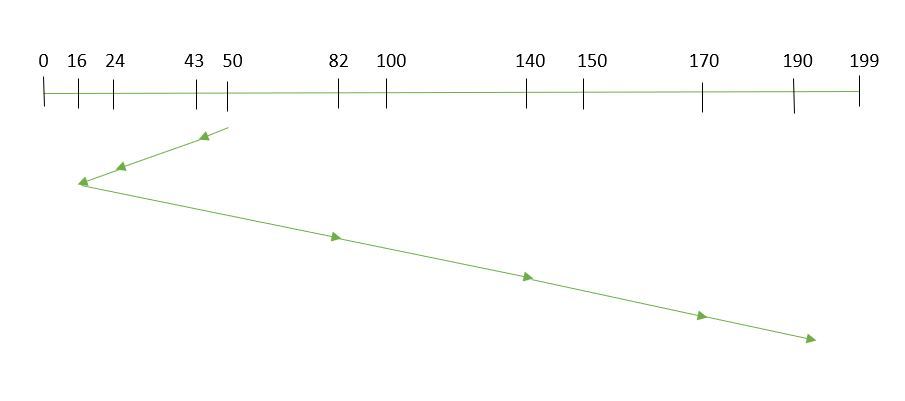
SSTF Processing Steps
1. Current Position: 50
- Find the Closest Request:
- Distance to 82: |82 – 50| = 32
- Distance to 170: |170 – 50| = 120
- Distance to 43: |43 – 50| = 7
- Distance to 140: |140 – 50| = 90
- Distance to 24: |24 – 50| = 26
- Distance to 16: |16 – 50| = 34
- Distance to 190: |190 – 50| = 140
- Move to 43:
- Seek Time: 7 tracks
2. Current Position: 43
- Find the Closest Request:
- Distance to 82: |82 – 43| = 39
- Distance to 170: |170 – 43| = 127
- Distance to 24: |24 – 43| = 19
- Distance to 16: |16 – 43| = 27
- Distance to 190: |190 – 43| = 147
- Distance to 140: |140 – 43| = 97
- Move to 24:
- Seek Time: 19 tracks
3. Current Position: 24
- Find the Closest Request:
- Distance to 82: |82 – 24| = 58
- Distance to 170: |170 – 24| = 146
- Distance to 16: |16 – 24| = 8
- Distance to 140: |140 – 24| = 116
- Distance to 190: |190 – 24| = 166
- Move to 16:
- Seek Time: 8 tracks
4. Current Position: 16
- Find the Closest Request:
- Distance to 82: |82 – 16| = 66
- Distance to 170: |170 – 16| = 154
- Distance to 140: |140 – 16| = 124
- Distance to 190: |190 – 16| = 174
- Move to 82:
- Seek Time: 66 tracks
5. Current Position: 82
- Find the Closest Request:
- Distance to 170: |170 – 82| = 88
- Distance to 140: |140 – 82| = 58
- Distance to 190: |190 – 82| = 108
- Move to 140:
- Seek Time: 58 tracks
6. Current Position: 140
- Find the Closest Request:
- Distance to 170: |170 – 140| = 30
- Distance to 190: |190 – 140| = 50
- Move to 170:
- Seek Time: 30 tracks
7. Current Position: 170
- Move to 190:
- Seek Time: |190 – 170| = 20 tracks
Total Seek Time Calculation
Now, we calculate the total seek time by summing up the seek times for each move:Total Seek Time=7+19+8+66+58+30+20=208 tracks\text{Total Seek Time} = 7 + 19 + 8 + 66 + 58 + 30 + 20 = 208 \text{ tracks}Total Seek Time=7+19+8+66+58+30+20=208 tracks
SSTF Sequence
Here’s the sequence in which the read/write head will move using SSTF:
- Start: 50
- Move to: 43
- Move to: 24
- Move to: 16
- Move to: 82
- Move to: 140
- Move to: 170
- Move to: 190
Conclusion
Using the SSTF policy, the total seek time for the given requests is 208 tracks. SSTF efficiently handles requests by minimizing the seek time for each request but may lead to starvation for requests that are farther away, especially if there are many nearby requests.
3. SCAN (Elevator Algorithm)
Description: The SCAN algorithm, also known as the elevator algorithm, moves the disk arm (head) in one direction and services all requests in its path until it reaches the end of the disk. Upon reaching the end, the disk arm reverses direction and continues servicing requests in the new direction. This approach mimics the movement of an elevator, hence the name.
How It Works:
- Movement in One Direction: The disk arm starts moving in one direction (e.g., from the outer edge to the inner edge) and services all requests in its path.
- Reverse Direction: Once the disk arm reaches the end of the disk, it reverses direction (e.g., from the inner edge back to the outer edge) and services requests in the new direction.
- Service Requests: Requests that fall in the path of the disk arm are serviced as it moves. The arm does not skip any request in its current direction until it reaches the end.
Advantages:
- Reduced Starvation: Unlike SSTF, which may cause starvation for distant requests, SCAN ensures that every request will eventually be serviced as the arm reverses direction.
- Predictable Wait Times: Requests closer to the direction of movement are serviced faster, leading to a more predictable service pattern compared to FCFS.
Disadvantages:
- Uneven Service Times: Requests located in the direction opposite to the current movement may experience longer wait times, as they will only be serviced after the arm completes a full sweep.
- Increased Seek Time: Although SCAN reduces seek time compared to FCFS, the arm must travel to the end of the disk before reversing direction, which can lead to additional seek time.
Example:
Initial Setup
- Current Position of the Read/Write Arm: 50
- Order of Requests: 82, 170, 43, 140, 24, 16, 190
- Direction of Movement: Towards larger values
SCAN Processing Steps
1. Move in the Direction of Larger Values
The SCAN policy moves the disk arm in one direction, servicing all requests in that direction until it reaches the end of the disk, then reverses direction to service the remaining requests.
2. Serving Requests
- Current Position: 50
- Move from 50 to 82:
- Request: 82
- Move from 82 to 140:
- Request: 140
- Move from 140 to 170:
- Request: 170
- Move from 170 to 190:
- Request: 190
3. Reversal and Serve Remaining Requests
- Reverse Direction: Move back towards the beginning of the disk.
- Move from 190 to 140 (backtrack):
- Request: 140 (already served, continue backward)
- Move from 140 to 82 (backtrack):
- Request: 82 (already served, continue backward)
- Move from 82 to 50 (backtrack):
- Position: 50 (initial position)
- Move from 50 to 24:
- Request: 24
- Move from 24 to 16:
- Request: 16
- Move from 16 to 43:
- Request: 43
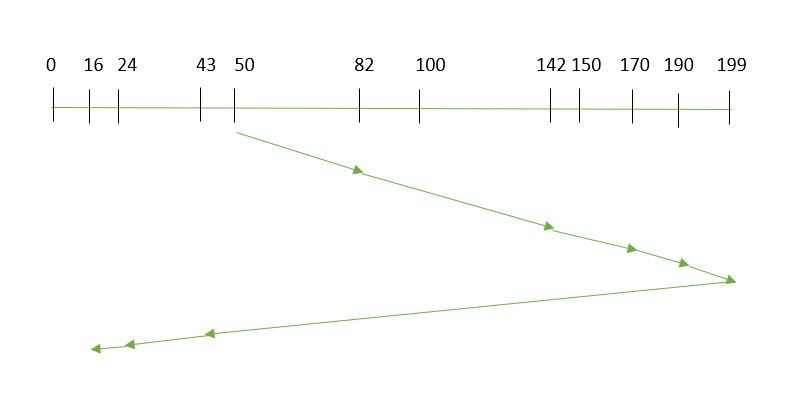
Total Seek Time Calculation
To calculate the seek time, compute the distance the arm travels between requests and include the reversal distance.
- From 50 to 82:
- Seek Distance: 82 – 50 = 32 tracks
- From 82 to 140:
- Seek Distance: 140 – 82 = 58 tracks
- From 140 to 170:
- Seek Distance: 170 – 140 = 30 tracks
- From 170 to 190:
- Seek Distance: 190 – 170 = 20 tracks
- From 190 to 50 (reversal):
- Seek Distance: 190 – 50 = 140 tracks
- From 50 to 24:
- Seek Distance: 50 – 24 = 26 tracks
- From 24 to 16:
- Seek Distance: 24 – 16 = 8 tracks
- From 16 to 43:
- Seek Distance: 43 – 16 = 27 tracks
Total Seek Time Calculation:Total Seek Time=32+58+30+20+140+26+8+27=341 tracks\text{Total Seek Time} = 32 + 58 + 30 + 20 + 140 + 26 + 8 + 27 = 341 \text{ tracks}Total Seek Time=32+58+30+20+140+26+8+27=341 tracks
SCAN Sequence
Here’s the sequence in which the read/write arm will move using SCAN:
- Start: 50
- Move to: 82
- Move to: 140
- Move to: 170
- Move to: 190
- Reverse Direction: Move back to 50
- Move to: 24
- Move to: 16
4. C-SCAN (Circular SCAN)
Description: The C-SCAN (Circular SCAN) algorithm is a variation of the SCAN algorithm designed to address some of its limitations, particularly the issue of long wait times for requests that are not in the immediate path of the disk arm. In C-SCAN, the disk arm moves in one direction, services all requests in that direction, and upon reaching the end of the disk, it jumps back to the beginning of the disk to continue servicing requests in the same direction. This creates a circular or cyclic pattern, which ensures that all requests are eventually serviced without the need to reverse direction.
How It Works:
- Movement in One Direction: The disk arm moves in one direction (e.g., from the outer edge to the inner edge), servicing all requests in its path.
- Jump to Start: When the disk arm reaches the end of the disk, it jumps back to the beginning (or starting track) without servicing requests during the return trip.
- Continue Servicing: After the jump, the arm resumes servicing requests in the same direction it was initially moving.
Advantages:
- Uniform Wait Time: By eliminating the need to reverse direction, C-SCAN provides more uniform wait times for requests, as the arm consistently moves in one direction.
- Reduced Starvation: Ensures that all requests are eventually serviced without excessive delay, as the arm cycles through the disk.
Disadvantages:
- Potential Latency: The jump from the end of the disk back to the beginning can introduce a small delay, though it is generally less than the time spent reversing direction in SCAN.
- Uneven Distribution: The algorithm might still result in uneven servicing times if many requests are clustered in one part of the disk and few are in others.
Example:
Initial Setup
- Current Position of the Read/Write Arm: 50
- Order of Requests: 82, 170, 43, 140, 24, 16, 190
- Direction of Movement: Towards larger values
C-SCAN Processing Steps
1. Move in the Direction of Larger Values
The C-SCAN policy moves the disk arm in one direction, servicing all requests in that direction until it reaches the end of the disk, then wraps around to the beginning of the disk to continue servicing the remaining requests.
2. Serving Requests
- Current Position: 50
- Move from 50 to 82:
- Request: 82
- Move from 82 to 140:
- Request: 140
- Move from 140 to 170:
- Request: 170
- Move from 170 to 190:
- Request: 190
At this point, the arm has reached the highest request. In C-SCAN, the arm then wraps around to the lowest value and continues to serve the remaining requests.
3. Wrap Around to the Beginning
- Wrap Around: Move from 190 to 0 (assuming the disk wraps around to the start) and continue serving requests from the beginning.
- Move from 190 to 16 (wrap around):
- Request: 16
- Move from 16 to 24:
- Request: 24
- Move from 24 to 43:
- Request: 43
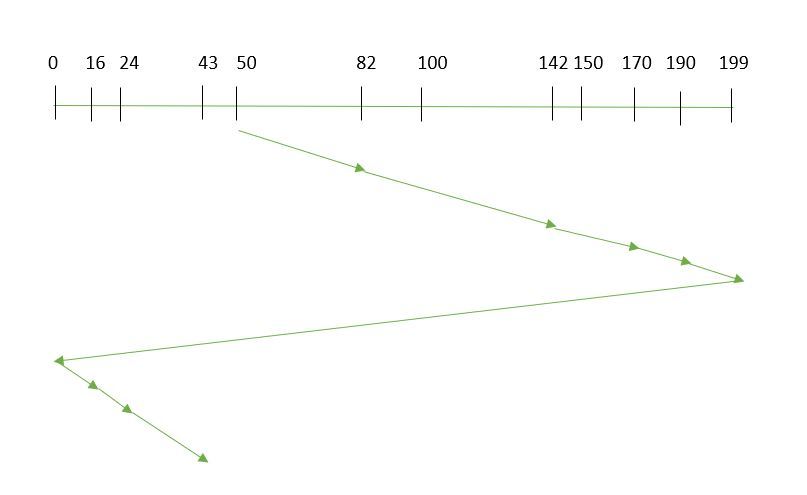
Total Seek Time Calculation
To calculate the seek time, compute the distance the arm travels between requests and include the wrap-around distance.
- From 50 to 82:
- Seek Distance: 82 – 50 = 32 tracks
- From 82 to 140:
- Seek Distance: 140 – 82 = 58 tracks
- From 140 to 170:
- Seek Distance: 170 – 140 = 30 tracks
- From 170 to 190:
- Seek Distance: 190 – 170 = 20 tracks
- Wrap Around from 190 to 0:
- Seek Distance: 190 – 0 = 190 tracks (assuming a full disk wrap)
- From 0 to 16:
- Seek Distance: 16 – 0 = 16 tracks
- From 16 to 24:
- Seek Distance: 24 – 16 = 8 tracks
- From 24 to 43:
- Seek Distance: 43 – 24 = 19 tracks
Total Seek Time Calculation:Total Seek Time=32+58+30+20+190+16+8+19=383 tracks\text{Total Seek Time} = 32 + 58 + 30 + 20 + 190 + 16 + 8 + 19 = 383 \text{ tracks}Total Seek Time=32+58+30+20+190+16+8+19=383 tracks
C-SCAN Sequence
Here’s the sequence in which the read/write arm will move using C-SCAN:
- Start: 50
- Move to: 82
- Move to: 140
- Move to: 170
- Move to: 190
- Wrap Around: Move from 190 to 16
- Move to: 24
- Move to: 43
Introduction to Files System and Protection
A file system is a method and data structure that an operating system uses to manage files on a disk or other storage devices. It provides an interface between the user and the hardware, allowing users to create, read, write, and manage files. File systems also handle the organization of files and directories, ensuring data integrity, and optimizing access and storage.
Key Concepts in File Systems
- Files: Basic units of storage that contain data. Files can be of various types, including text, binary, or executable files.
- Directories: Also known as folders, directories are containers that hold files and other directories. They help in organizing files into a hierarchical structure.
- File Metadata: Information about files, including file name, size, type, creation date, modification date, and permissions.
- File Operations: Common operations include creating, reading, writing, deleting, and renaming files.
- Storage Allocation: File systems manage how data is stored on a disk. This can include allocation strategies like contiguous allocation, linked allocation, or indexed allocation.
- File System Hierarchy: Organizes files and directories into a tree-like structure. For example, in Unix-based systems, the root directory (“/”) is at the top of the hierarchy.
Types of File Systems
- FAT (File Allocation Table):
- Used in: Older systems and removable storage (e.g., USB drives).
- Features: Simple structure, limited file size and partition size.
- Variants: FAT16, FAT32.
- NTFS (New Technology File System):
- Used in: Windows operating systems.
- Features: Supports large files and volumes, file permissions, encryption, and journaling.
- ext (Extended File System):
- Used in: Linux operating systems.
- Features: Ext2 (no journaling), Ext3 (with journaling), Ext4 (improved performance and features).
- HFS+ (Hierarchical File System Plus):
- Used in: macOS (prior to APFS).
- Features: Journaling, supports large files and volumes.
- APFS (Apple File System):
- Used in: Modern macOS and iOS.
- Features: Enhanced performance, encryption, and snapshots.
- XFS:
- Used in: Linux.
- Features: High-performance, scalability for large files and volumes, journaling.
File System Protection
File system protection is essential to ensure the integrity, confidentiality, and availability of files. It involves mechanisms to prevent unauthorized access, data corruption, and loss.
Key Aspects of File System Protection
- Access Control:
- Permissions: Define who can read, write, or execute a file. Common permission settings include read (r), write (w), and execute (x).
- Access Control Lists (ACLs): Provide more granular permissions than traditional Unix permissions.
- File Encryption:
- At Rest: Encrypting files stored on disk to protect them from unauthorized access.
- In Transit: Encrypting data being transferred over networks to prevent interception.
- Data Integrity:
- Checksums and Hashing: Used to verify that files have not been corrupted or altered.
- Journaling: Ensures that changes to the file system are recorded so that recovery is possible in case of a crash.
- Backup and Recovery:
- Regular Backups: Creating copies of files and directories to restore them in case of loss or corruption.
- Snapshots: Capturing the state of the file system at a particular point in time for recovery purposes.
- File System Quotas:
- Limits: Restrict the amount of disk space or number of files a user or group can use.
- Access Logging:
- Audit Trails: Logging access to files to detect and investigate unauthorized access or changes.
Summary
A file system provides the structure and methods for storing and accessing files on a storage medium. It includes various types, each with its own features and advantages. File system protection mechanisms are crucial for maintaining data security, integrity, and availability. By implementing access controls, encryption, data integrity checks, backups, quotas, and logging, file systems ensure that data remains secure and accessible only to authorized users.
File management
File management is a crucial aspect of operating systems that involves organizing, accessing, and maintaining files and directories on a storage device. It encompasses a range of tasks and functionalities aimed at ensuring efficient storage, retrieval, and security of files. Here’s an overview of key components and practices related to file management:
Key Components of File Management
- File Organization:
- Directories and Subdirectories: Files are organized into directories (or folders), which can contain other directories. This hierarchical structure helps manage and locate files efficiently.
- File Naming: Files are identified by names, which typically include an extension indicating the file type (e.g.,
.txt,.jpg).
- File Operations:
- Creation: The process of making a new file. The file system allocates space and assigns metadata.
- Reading: Accessing the content of a file. This involves opening the file and retrieving its data.
- Writing: Modifying or adding data to a file. This operation updates the file’s content.
- Deletion: Removing a file from the file system. The space previously occupied by the file is marked as available for new data.
- Renaming: Changing the name of a file while keeping its content and attributes intact.
- File Attributes and Metadata:
- File Size: The amount of disk space the file occupies.
- Creation Date: When the file was created.
- Modification Date: When the file was last modified.
- Access Date: When the file was last accessed.
- Permissions: Define who can read, write, or execute the file.
- File Access Methods:
- Sequential Access: Reading or writing data in a linear order from the beginning to the end of the file.
- Direct (Random) Access: Accessing data at any location within the file directly, which allows for non-sequential access.
- File Allocation Methods:
- Contiguous Allocation: Files are stored in a single contiguous block of memory. This method is simple but can lead to fragmentation.
- Linked Allocation: Files are stored in non-contiguous blocks linked together through pointers. This method reduces fragmentation but can be slower for accessing files.
- Indexed Allocation: Uses an index block to keep track of all file blocks, allowing for efficient random access and reduced fragmentation.
- File System Management:
- Disk Quotas: Limit the amount of disk space a user or group can consume, helping to manage storage resources.
- File System Check (fsck): A utility for checking the consistency of the file system and repairing errors.
- Defragmentation: Reorganizing fragmented files to improve access times and reduce disk wear.
File Management Tasks
- File Searching:
- Basic Search: Locating files based on names or attributes.
- Advanced Search: Using criteria such as content, metadata, or file type.
- File Backup and Recovery:
- Backup: Creating copies of files or directories to safeguard against data loss.
- Recovery: Restoring files from backups or recovering files after accidental deletion.
- File Versioning:
- Version Control: Keeping track of changes to files, especially useful for documents and code. Allows users to revert to previous versions if needed.
- File Synchronization:
- Synchronization: Ensuring that files are consistent across different locations, such as between a local drive and a cloud storage service.
- Access Control and Security:
- Permissions Management: Setting and enforcing access controls to ensure that only authorized users can access or modify files.
- Encryption: Protecting files from unauthorized access by encoding their contents.
Practical Examples
- File Management in Windows:
- File Explorer: A graphical interface for managing files and directories.
- Command Prompt: Offers command-line tools for file operations (e.g.,
copy,del,move).
- File Management in Linux:
- File Manager: Various graphical file managers like Nautilus or Dolphin.
- Terminal Commands: Commands like
ls,cp,mv,rmfor file management.
Summary
Effective file management is essential for maintaining an organized, efficient, and secure storage environment. It involves managing the creation, access, and organization of files and directories, as well as implementing practices for backup, recovery, and security. By understanding and utilizing file management principles, users can ensure that their data is well-organized, easily accessible, and protected from loss or unauthorized access.
File operations are fundamental activities involved in managing files on a storage system. These operations enable users and applications to interact with files for various purposes. Here’s a detailed overview of common file operations:
1. File Creation
Definition: The process of creating a new file in the file system.
Steps:
- Allocate space on the storage device.
- Assign a name and initial metadata to the file (e.g., creation date, size).
Example:
- In Unix/Linux:
touch filenameorecho "" > filename - In Windows: Right-click in File Explorer, choose “New” and then “Text Document.”
Use Case: Creating a new document, configuration file, or program file.
2. File Opening
Definition: The process of accessing a file to read from or write to it.
Steps:
- Locate the file in the file system.
- Load the file’s metadata and open a file descriptor or handle for the operation.
Example:
- In Unix/Linux:
open("filename", O_RDWR)(using system calls in C) - In Python:
open("filename", "r")oropen("filename", "w")
Use Case: Opening a file to view its contents or edit it.
3. File Reading
Definition: The process of retrieving data from a file.
Steps:
- Position the file pointer at the desired location (if not reading sequentially).
- Read data from the file into a buffer or variable.
Example:
- In Unix/Linux:
read(fd, buffer, size)(using system calls in C) - In Python:
file.read()orfile.readline()
Use Case: Reading the contents of a text file or binary data.
4. File Writing
Definition: The process of modifying or adding data to a file.
Steps:
- Position the file pointer at the desired location (if not writing sequentially).
- Write data from a buffer or variable to the file.
Example:
- In Unix/Linux:
write(fd, buffer, size)(using system calls in C) - In Python:
file.write(data)
Use Case: Writing data to a log file, saving changes to a document.
5. File Deletion
Definition: The process of removing a file from the file system.
Steps:
- Locate the file.
- Mark the space occupied by the file as available for new data.
- Remove the file’s entry from the directory structure.
Example:
- In Unix/Linux:
rm filename - In Windows:
del filename
Use Case: Removing obsolete files or cleaning up disk space.
6. File Renaming
Definition: The process of changing the name of a file while keeping its content and metadata intact.
Steps:
- Locate the file.
- Update the file’s entry in the directory structure with the new name.
Example:
- In Unix/Linux:
mv oldname newname - In Windows:
rename oldname newname
Use Case: Organizing files by renaming them for clarity.
7. File Copying
Definition: The process of creating a duplicate of a file.
Steps:
- Read the contents of the original file.
- Write the contents to a new file.
Example:
- In Unix/Linux:
cp sourcefile destinationfile - In Windows:
copy sourcefile destinationfile
Use Case: Backing up files or creating versions of a document.
8. File Moving
Definition: The process of changing the location of a file within the file system.
Steps:
- Locate the file.
- Remove the file from its current location.
- Place the file in the new location.
Example:
- In Unix/Linux:
mv filename /path/to/new/location/ - In Windows:
move filename \path\to\new\location\
Use Case: Organizing files into different directories or drives.
9. File Appending
Definition: The process of adding data to the end of a file without modifying its existing content.
Steps:
- Open the file in append mode.
- Write data to the end of the file.
Example:
- In Unix/Linux:
echo "new data" >> filename - In Python:
file = open("filename", "a")andfile.write("new data")
Use Case: Adding log entries to a log file or appending data to a text file.
10. File Locking
Definition: The process of controlling access to a file to prevent concurrent modifications.
Steps:
- Request a lock on the file.
- Access the file while the lock is held.
- Release the lock when done.
Example:
- In Unix/Linux: Use
flocksystem call orfcntlfor advisory locks. - In Windows: Use
LockFilefunction.
Use Case: Preventing data corruption when multiple processes or users access a file simultaneously.
11. File Closing
Definition: The process of closing a file after completing operations on it.
Steps:
- Flush any remaining data to disk.
- Release the file descriptor or handle.
Example:
- In Unix/Linux:
close(fd)(using system calls in C) - In Python:
file.close()
Use Case: Ensuring that all changes are saved and resources are freed.
Summary
File operations encompass a range of activities related to managing files on a storage system. These operations include creating, opening, reading, writing, deleting, renaming, copying, moving, appending, locking, and closing files. Understanding these operations is crucial for effective file management, ensuring data integrity, and maintaining an organized file system.
Various Access Methods
1. Sequential Access
Definition: Sequential access involves reading or writing data in a linear, continuous manner from the beginning to the end of the file. Data is processed in the order it appears.
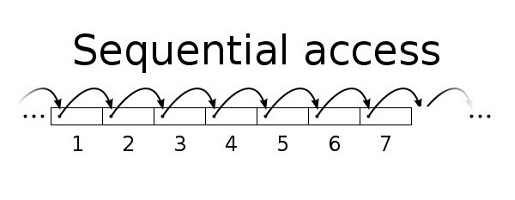
Characteristics:
- Linear Processing: The file pointer moves from the start to the end of the file, processing data in a sequential order.
- Efficient for Streaming: Suitable for tasks that involve processing data as a stream, such as reading log files or streaming media.
Operations:
- Reading: Data is read sequentially from the start of the file. For example, reading a text file line by line.
- Writing: Data is appended to the end of the file, or new data is written in the order it is received.
Example:
- Text Files: Opening a text file and reading each line one after another.
- Log Files: Continuously writing new log entries to the end of a log file.
Usage:
- Ideal for scenarios where data is processed in the order it was written, such as reading logs, streaming video, or processing large data files sequentially.
Advantages:
- Simplicity: Easier to implement and manage.
- Efficient for Sequential Tasks: Works well for tasks that naturally follow a linear order.
Disadvantages:
- Inefficiency for Random Access: Not suitable for scenarios where data needs to be accessed in a non-sequential manner or where only specific portions of the file are needed.
2. Direct (Random) Access
Definition: Direct access, also known as random access, allows for reading or writing data at any location within the file without having to process data sequentially. This method provides the ability to jump to a specific position in the file.

Characteristics:
- Non-Sequential Access: The file pointer can be moved to any location in the file to read or write data directly.
- Efficient for Random Access: Ideal for applications where data needs to be accessed or updated at arbitrary positions.
Operations:
- Reading: Data can be accessed at any position in the file. For instance, retrieving a specific record from a database file.
- Writing: Data can be written to any location, allowing updates or modifications at specific points in the file.
Example:
- Databases: Retrieving a record based on an index without having to read through the entire file.
- Spreadsheets: Accessing or updating specific cells directly.
Usage:
- Suitable for applications requiring frequent access to various parts of a file, such as database management systems, file systems with large datasets, or applications that need to modify specific portions of a file.
Advantages:
- Flexibility: Allows quick access to different parts of the file without sequentially processing all data.
- Efficient for Random Access: Reduces the time needed to retrieve or modify specific data points.
Disadvantages:
- Complexity: Implementation is more complex compared to sequential access, especially for managing file pointers and data integrity.
Understanding these access methods helps in designing systems and applications based on their specific data access needs, optimizing performance, and ensuring efficient data handling.
3.Indexed Access
Definition: Indexed access uses an index structure to facilitate efficient data retrieval from a file. The index maps keys to specific locations within the file, enabling quick access to the data based on these keys.
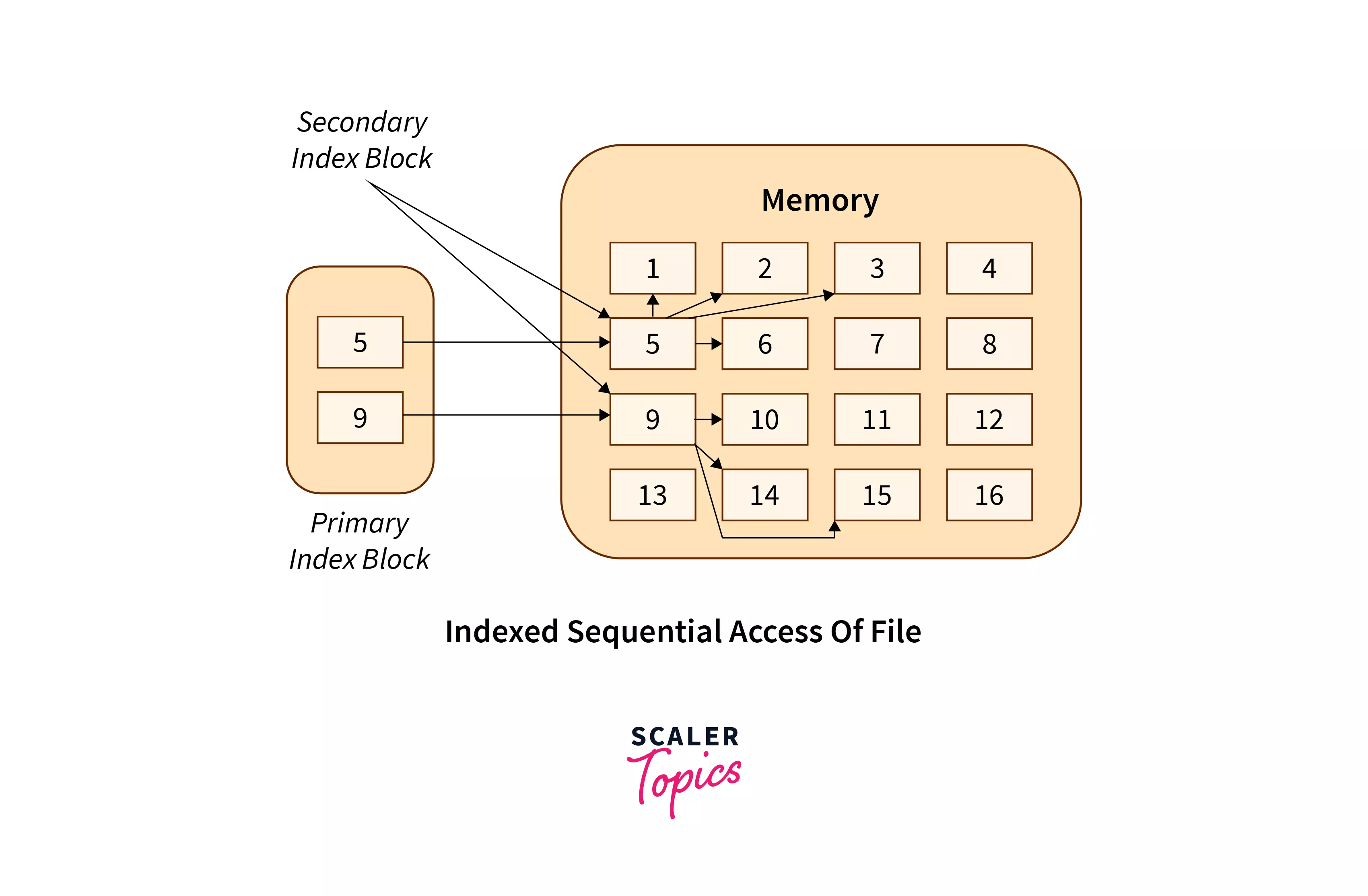
Characteristics:
- Index Structure: An index is a separate data structure that contains keys and pointers to the locations of the corresponding data within the file.
- Efficient Lookup: Provides fast access to data by using the index to directly locate data items based on keys.
How It Works:
- Index Creation: An index is built when the file is created or updated. It maps data keys (or values) to their locations in the file.
- Data Retrieval: To access a specific piece of data, the system first looks up the key in the index. The index provides the file location of the data, allowing the system to retrieve it directly.
Types of Indexes:
- Single-Level Index: A simple index where each key directly maps to a file location. Suitable for smaller datasets.
- Multi-Level Index: Uses multiple levels of indexing (e.g., primary and secondary indexes) to manage larger datasets efficiently. Often used in databases.
Example:
- Databases: Indexes are used to speed up query performance by providing quick access to records based on indexed fields (e.g., searching for a customer by their ID).
- File Systems: Modern file systems like NTFS or ext4 use indexing to efficiently locate files and directories.
Usage:
- Databases: Indexes improve query performance by enabling fast searches, lookups, and sorting operations.
- Search Engines: Indexes are used to quickly find relevant documents or web pages based on search queries.
Advantages:
- Speed: Significantly reduces the time required to locate and access data compared to sequential search methods.
- Efficiency: Provides quick access even for large datasets, making it suitable for applications with frequent data retrieval needs.
Disadvantages:
- Overhead: Maintaining an index requires additional storage space and processing time, especially during data updates or insertions.
- Complexity: Indexing can add complexity to file management and data retrieval processes.
Summary: Indexed access improves data retrieval efficiency by using an index structure to map keys to file locations. This method is particularly useful for applications that require fast searches and retrievals, such as database management systems and search engines. While it offers significant performance benefits, it also introduces additional complexity and overhead in managing the index.
Various Allocation Methods
File allocation methods determine how files are stored on a disk. Different methods have different trade-offs regarding efficiency, fragmentation, and performance. Here’s an overview of various file allocation methods:
1. Contiguous Allocation
Definition: In contiguous allocation, a file is stored in a single, contiguous block of memory on the disk. This means that all the blocks allocated to a file are adjacent to each other.
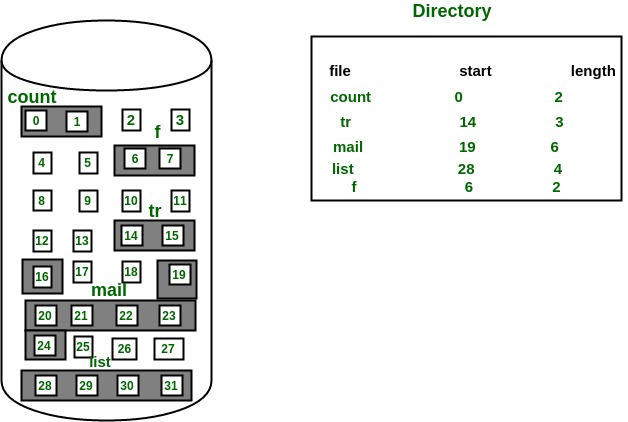
Characteristics:
- Linear Storage: The file occupies a series of consecutive disk blocks, meaning the entire file is stored in a continuous section of the disk.
- Simple Implementation: Easy to manage because the file’s data is stored in a straightforward, uninterrupted sequence.
Advantages:
- Fast Access: Access times are minimized because the file is read or written in a single, contiguous block. There is minimal disk head movement, resulting in faster performance.
- No Internal Fragmentation: Since the file is stored contiguously, there is no wasted space within the allocated blocks.
Disadvantages:
- External Fragmentation: Over time, as files are created and deleted, free disk space can become fragmented into small, non-contiguous pieces. This makes it difficult to find a large enough contiguous block for new files or for growing existing files.
- Fixed Size: Once allocated, the size of the file’s storage cannot easily be adjusted. If a file needs more space than initially allocated, it must be moved or the file system must be reorganized to accommodate the expansion.
Use Case:
- Static Files: Ideal for files with predictable sizes that do not frequently change, such as system files or static data files. It is also used in simpler file systems where ease of implementation is a priority.
2. Linked Allocation
Definition: In linked allocation, a file is stored in non-contiguous blocks, with each block containing a pointer to the next block in the sequence. This creates a linked list of blocks.
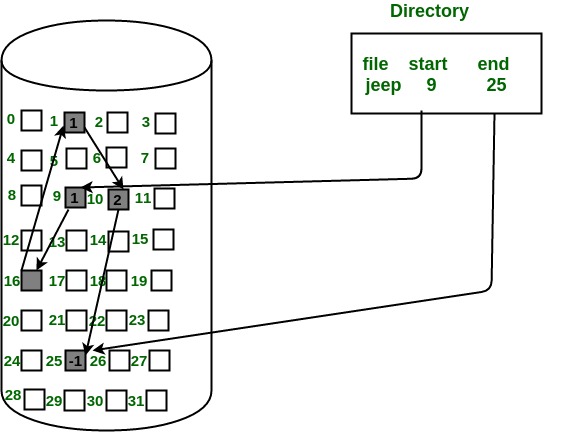
Characteristics:
- Linked Blocks: Each block in the file contains a pointer to the next block, allowing the file to be scattered across different parts of the disk.
- Dynamic Size: Files can easily grow by linking additional blocks, without needing to find a contiguous space.
Advantages:
- No External Fragmentation: Since blocks can be scattered, there is no issue with external fragmentation. Free space on the disk can be utilized more flexibly.
- Flexible Growth: Files can expand dynamically as more blocks are added, accommodating changes in file size without moving existing data.
Disadvantages:
- Overhead: Each block contains a pointer to the next block, which adds overhead and reduces the effective storage space available for data.
- Access Speed: Sequential access is straightforward and efficient, but random access can be slower. To access a particular block, the system must follow the chain of pointers, which can add latency.
Use Case:
- Files of Variable Size: Suitable for file systems where files frequently change in size or where files are of unpredictable lengths. Common in early file systems and certain types of file storage systems.
3. Indexed Allocation
Definition: In indexed allocation, an index block is used to keep track of all the blocks that a file occupies. The index block contains pointers to each block of the file.
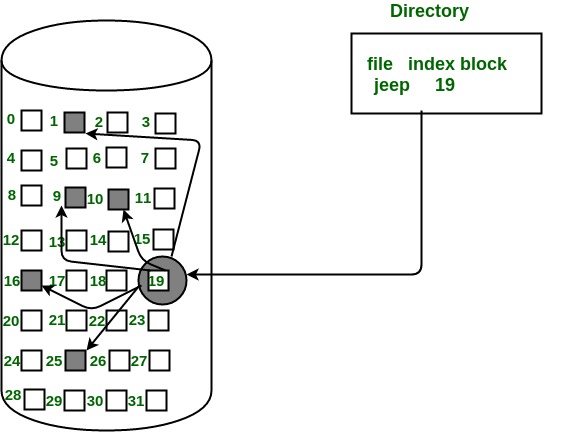
Characteristics:
- Index Block: A special block that holds pointers to all the data blocks of a file, allowing direct access to any part of the file.
- Efficient Random Access: Provides the ability to access any block of the file directly, making it easy to retrieve or update data at specific locations.
Advantages:
- Efficient Random Access: Allows for quick access to any data block without needing to follow a sequence of pointers. This is useful for operations that require frequent random access to data.
- No External Fragmentation: Handles fragmentation internally by using an index block, so files can be stored non-contiguously without affecting access efficiency.
Disadvantages:
- Index Overhead: Requires additional space for the index block. For very large files, this index may need to be multi-level, adding complexity.
- Index Management: Managing the index block and keeping it up-to-date can add overhead, especially when files are frequently updated or resized.
Use Case:
- Modern File Systems: Used in modern file systems such as NTFS and ext4, which require efficient random access and handle a variety of file sizes. It is also common in databases and systems with large amounts of data that benefit from quick retrieval times.
These allocation methods offer different trade-offs in terms of efficiency, complexity, and performance, making them suitable for various types of applications and storage needs.
Directory Structure Organization
Directory structures are essential for managing files and directories on a disk. They help organize and locate files efficiently. Here’s an overview of common directory structure organizations:
Single-Level Directory
Definition: A single-level directory structure is the most basic form of file organization, where all files are stored in a single directory without any subdirectories.

Characteristics:
- Flat Structure: All files are located directly within the root directory. There are no nested or hierarchical directories.
- Simple Implementation: Easy to implement and manage due to its straightforward layout.
Advantages:
- Simplicity: The absence of subdirectories makes the structure easy to understand and navigate, especially for small numbers of files.
- Quick Access: Accessing files is fast when the number of files is small because there’s no need to traverse multiple directory levels.
Disadvantages:
- Scalability Issues: As the number of files increases, managing and locating specific files can become challenging. A large number of files in a single directory can lead to clutter.
- Lack of Organization: Without subdirectories, it is difficult to categorize or group files logically, which can lead to inefficiencies in file management.
Real-Life Example:
Early Personal Computers: In the early days of personal computing, many operating systems, such as MS-DOS, used a single-level directory structure. For example, MS-DOS had a root directory where all files, including system files, application files, and user files, were stored in a flat layout. This made it straightforward to access files, but as users began to accumulate more files, the limitations of this approach became apparent, leading to the development of more sophisticated directory structures.
Two-Level Directory
Definition: A two-level directory structure consists of a root directory and a single level of subdirectories. Each subdirectory can contain files, but no further subdirectories are allowed.
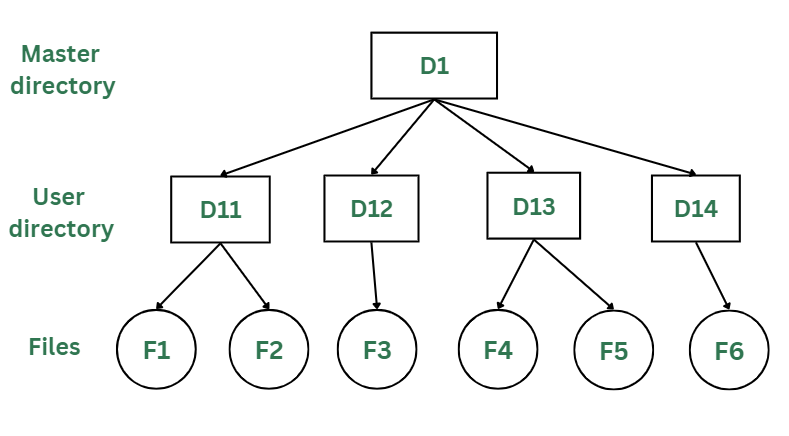
Characteristics:
- Root Directory: Contains a set of subdirectories, each of which can hold files.
- Basic Hierarchy: Provides a simple hierarchical organization with one level of grouping.
Advantages:
- Improved Organization: Files can be grouped into subdirectories, making it easier to manage and locate them compared to a single-level directory.
- Better Scalability: Handles a moderate number of files better than a single-level directory by distributing files across multiple subdirectories.
Disadvantages:
- Limited Hierarchy: Only one level of subdirectories restricts the depth of file organization. This can be limiting for more complex file management needs.
- Duplication Potential: Some files might need to be duplicated across different subdirectories if they belong to multiple categories.
Real-Life Example:
Early PC Operating Systems: In earlier versions of the Windows operating system, such as Windows 3.x, the file system used a two-level directory structure. The root directory contained subdirectories like Program Files, Windows, and Documents. Each subdirectory could hold files relevant to its category, improving file organization compared to a flat structure but still lacking the depth of more modern hierarchical systems.
Hierarchical Directory (Tree Structure)
Definition: A hierarchical directory structure, or tree structure, organizes files in a multi-level hierarchy, allowing directories to contain subdirectories, which in turn can contain more subdirectories and files.
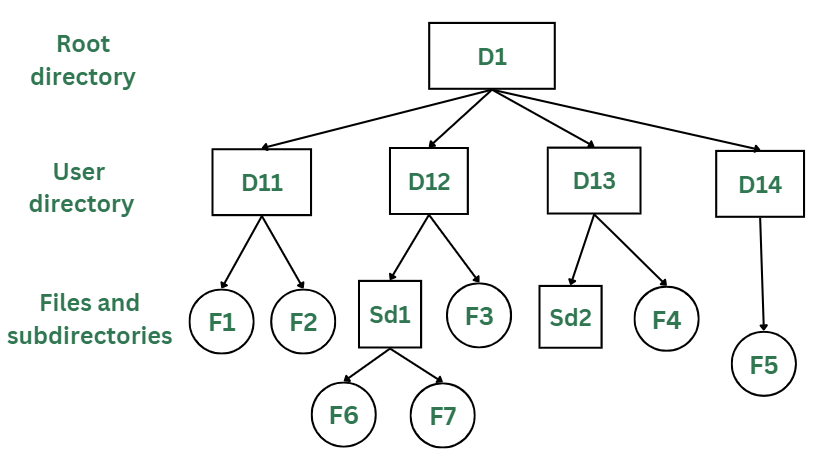
Characteristics:
- Tree Structure: Files and directories are arranged in a hierarchical manner, forming a tree-like structure with multiple levels of nesting.
- Flexible Organization: Provides a detailed and organized way to manage files and directories.
Advantages:
- Scalability: Handles large numbers of files and directories efficiently by using multiple levels of organization.
- Logical Organization: Allows for a logical grouping of files and directories, making it easier to manage and navigate complex file systems.
Disadvantages:
- Complexity: Can become complex with deep nesting and a large number of directories. Managing and navigating through many levels can be cumbersome.
- Long Paths: Long directory paths can be difficult to work with and may become unwieldy.
Real-Life Example:
Modern Operating Systems: Most contemporary operating systems, such as Windows, macOS, and Linux, use a hierarchical directory structure. For example, in Windows, you have a root directory (e.g., C:), which contains subdirectories like Users, Program Files, and Windows. Each of these directories contains further subdirectories and files, providing a detailed and organized structure for managing data. Similarly, in Linux, the / root directory contains subdirectories such as /home, /etc, and /usr, each of which further organizes files and directories.
File Protection
File protection involves mechanisms and strategies designed to safeguard files from unauthorized access, modification, or deletion. It ensures data security, integrity, and confidentiality. Here are key aspects of file protection:
1. Access Control
Definition: Access control mechanisms regulate who can view or modify files and directories.
Types:
- User Authentication: Verifies the identity of users accessing the system, typically through usernames and passwords. For example, in a corporate environment, employees log in with their credentials to access files on a shared network.
- Access Permissions: Define what actions users or groups can perform on files and directories. Common permissions include read, write, and execute. For example, in UNIX-like systems, the
chmodcommand sets file permissions to control access.
Example:
- Windows NTFS Permissions: In Windows, NTFS file system permissions allow setting detailed access controls for files and folders. For instance, a file might be configured so that only specific users or groups can read or modify it.
2. File Encryption
Definition: Encryption transforms files into a format that is unreadable without a decryption key, protecting data from unauthorized access.
Types:
- Symmetric Encryption: Uses a single key for both encryption and decryption. For example, AES (Advanced Encryption Standard) is commonly used for encrypting files.
- Asymmetric Encryption: Uses a pair of keys, one for encryption and one for decryption. For example, RSA (Rivest–Shamir–Adleman) is used for secure communications and file protection.
Example:
- Encrypted Archives: Files can be encrypted using tools like WinRAR or 7-Zip, which allow users to set passwords and encrypt the content of archives, ensuring that only those with the password can access the files.
3. File Integrity
Definition: Ensures that files remain unchanged and free from unauthorized modifications.
Techniques:
- Checksums and Hash Functions: Generate a unique value (hash) based on the file’s contents. Any change to the file will result in a different hash value, indicating potential tampering. For example, MD5 or SHA-256 hashes are used to verify file integrity.
- Digital Signatures: Use cryptographic methods to verify the authenticity and integrity of files. A digital signature ensures that the file has not been altered and verifies the source.
Example:
- Software Downloads: Websites often provide hash values for downloadable files. Users can compare these hashes with the downloaded file’s hash to ensure the file hasn’t been corrupted or tampered with.
4. Backup and Recovery
Definition: Involves creating copies of files and data to protect against data loss due to accidental deletion, corruption, or hardware failure.
Techniques:
- Regular Backups: Periodic copying of files to secure storage locations. For example, automated backup systems can create daily or weekly backups of important files.
- Versioning: Maintains multiple versions of files to recover from changes or deletions. For example, cloud storage services often support version history to restore previous file versions.
Example:
- Cloud Storage Services: Services like Google Drive or Dropbox offer backup and versioning features, allowing users to recover previous versions of files and restore deleted files from a backup.
5. Audit Trails and Monitoring
Definition: Tracks and records access and modifications to files, providing a history of who accessed or changed files and when.
Techniques:
- Logging: Records actions related to file access and modifications. For example, a file server might log all access attempts and changes to a specific file.
- Alerts: Notifies administrators of suspicious or unauthorized activities. For example, an intrusion detection system might alert if unusual access patterns are detected.
Example:
- File Server Logs: Enterprise file servers often maintain logs of file access and changes, which can be reviewed to detect unauthorized access or changes.
These file protection mechanisms help secure data from various threats, ensuring that files remain confidential, intact, and accessible only to authorized users.