
Introduction of DBMS & RDBMS
A Database Management System (DBMS) is a software system designed to facilitate the creation, organization, management, and retrieval of data from a database. It acts as an interface between the users and the database, allowing users to interact with the data in an efficient and secure manner. DBMS is used to store, modify, and extract information from a database and ensures that data is consistently organized and remains easily accessible.
Key Features of DBMS:
- Data Abstraction: Provides a logical view of the data to users, hiding the complexities of the underlying database structure.
- Data Independence: Allows changes to the database schema without affecting the application programs.
- Data Security: Ensures that only authorized users have access to the data.
- Data Integrity: Maintains accuracy and consistency of the data over its lifecycle.
- Concurrency Control: Manages simultaneous data access to ensure consistency and prevent conflicts.
- Backup and Recovery: Provides mechanisms for data recovery in case of system failures.
- Data Sharing: Allows multiple users to access the database concurrently.
Applications of DBMS and RDBMS in Real Life
1. Banking Systems
- Use of DBMS/RDBMS: Banks use DBMS to manage customer information, accounts, transactions, loans, and more. They require robust data management systems to ensure accuracy, security, and efficiency.
- Real-Life Example:
- Customer Accounts: Banks maintain customer data in tables, including details like account number, name, address, balance, and transaction history.
- Transactions: Each transaction (withdrawal, deposit, transfer) is recorded in a transaction table, linked to customer accounts via foreign keys.
- RDBMS Features Used:
- ACID Transactions: Ensure that transactions are completed accurately and consistently.
- Data Integrity: Foreign keys maintain relationships between customers and accounts.
- Security: Access controls prevent unauthorized access to sensitive data.
2. E-Commerce Platforms
- Use of DBMS/RDBMS: E-commerce websites use DBMS to manage product catalogs, customer information, orders, inventory, and payments.
- Real-Life Example:
- Product Catalog: Products are stored in a table with attributes like product ID, name, description, price, and stock quantity.
- Customer Orders: An orders table links customers to the products they’ve purchased, using foreign keys to reference both customer and product tables.
- RDBMS Features Used:
- Scalability: RDBMS can handle large volumes of data and user transactions efficiently.
- Data Relationships: Tables for products, customers, and orders are interlinked to maintain consistent data across the platform.
- SQL Queries: Enable complex search functions and reporting capabilities.
3. Healthcare Management Systems
- Use of DBMS/RDBMS: Hospitals and clinics use DBMS to store patient records, manage appointments, track treatments, and maintain inventory of medical supplies.
- Real-Life Example:
- Patient Records: Patient data, including medical history, prescriptions, and lab results, are stored in tables for easy access by healthcare providers.
- Appointments: A table of appointments links doctors and patients, ensuring efficient scheduling and tracking of visits.
- RDBMS Features Used:
- Data Security: Ensures that patient information is protected and only accessible to authorized personnel.
- Data Integrity: Consistency checks ensure accurate patient records and avoid duplicate entries.
- Data Relationships: Links between tables help track patients’ interactions with healthcare providers.
4. Education Systems
- Use of DBMS/RDBMS: Educational institutions use DBMS to manage student information, courses, grades, faculty data, and enrollment processes.
- Real-Life Example:
- Student Information System: Stores student details, enrollment status, and grades in interconnected tables.
- Course Management: Links students to courses and faculty, allowing for efficient tracking of academic progress.
- RDBMS Features Used:
- Normalization: Reduces data redundancy by organizing data into related tables.
- SQL Support: Enables the creation of complex reports on student performance and enrollment statistics.
- Data Relationships: Foreign keys maintain connections between students, courses, and faculty.
5. Social Media Platforms
- Use of DBMS/RDBMS: Social media platforms use DBMS to manage user profiles, posts, comments, likes, and connections between users.
- Real-Life Example:
- User Profiles: User data, such as name, email, and profile picture, is stored in a user table.
- Posts and Comments: Posts and comments are stored in related tables, with foreign keys linking them to user profiles.
- RDBMS Features Used:
- Scalability: Handles millions of users and interactions efficiently.
- Data Relationships: Links between users, posts, and comments facilitate interaction tracking.
- Security: Protects user data with authentication and access control measures.
Why RDBMS is Preferred in These Scenarios
- Structured Data: RDBMS provides a clear structure for data, making it easy to organize and query large datasets.
- Data Integrity: Ensures accuracy and consistency of data, which is critical in applications like banking and healthcare.
- SQL Support: Offers a powerful and flexible query language for data manipulation and retrieval.
- Complex Relationships: Efficiently manages complex relationships between different data entities.
- ACID Properties: Guarantees reliable transactions, crucial for financial and other sensitive operations.
In summary, DBMS and RDBMS play a crucial role in various real-life applications by providing structured, secure, and efficient data management solutions. Their features and capabilities make them indispensable tools for organizations across different sectors.
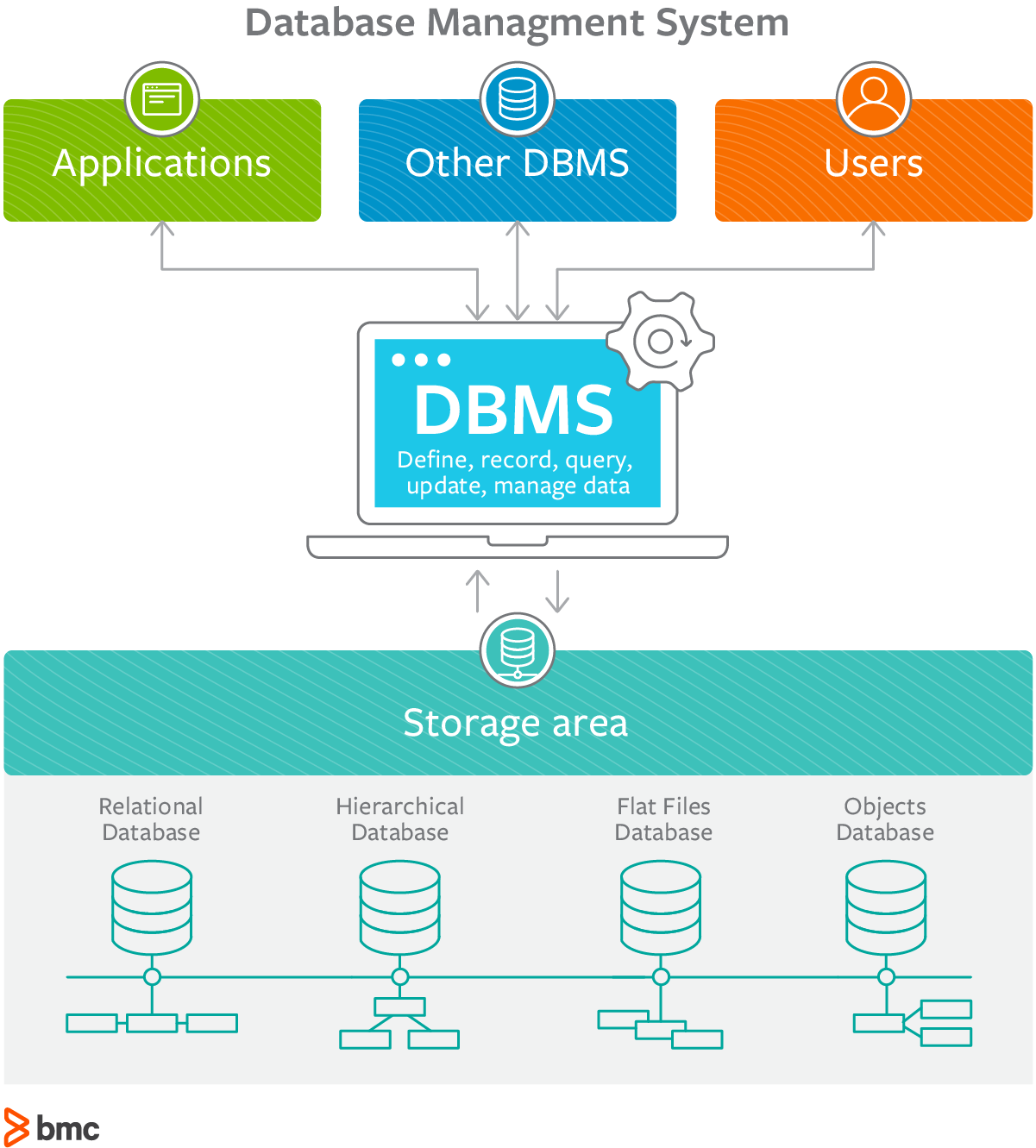
Database Management System (DBMS)?
A Database Management System (DBMS) is software that allows users to define, create, maintain, and control access to databases. It provides an interface between users and the database, enabling users to store, retrieve, update, and manage data in a structured and organized way.
Key Functions of a DBMS:
- Data Definition: Allows the creation and modification of database schemas. It defines the structure of data and relationships between data entities.
- Data Storage and Retrieval: Facilitates the storage of data and retrieval of data through queries. Users can efficiently access and manipulate data.
- Data Manipulation: Supports data insertion, updating, deletion, and querying through various commands and query languages.
- Data Security: Implements access control measures to protect data from unauthorized access and ensure data privacy.
- Data Integrity: Ensures data accuracy and consistency through constraints and validation rules.
- Data Backup and Recovery: Provides mechanisms to back up data and recover it in case of hardware or software failures.
- Concurrency Control: Manages simultaneous data access by multiple users, ensuring data consistency and integrity.
- Data Abstraction: Offers different levels of data abstraction, hiding the complexities of data storage from users.
Components of a DBMS:
- Database Engine: The core component that handles data storage, retrieval, and processing. It interacts with the database to perform operations and manage data.
- Database Schema: Defines the logical structure of the database, including tables, fields, relationships, and constraints.
- Query Processor: Translates user queries into low-level instructions that the database engine can execute. It optimizes query execution for efficiency.
- Transaction Manager: Manages database transactions, ensuring ACID properties (Atomicity, Consistency, Isolation, Durability) are maintained.
- Data Dictionary: Contains metadata about the database, such as table definitions, field types, constraints, and access permissions.
- User Interface: Provides tools and interfaces for users to interact with the database, such as command-line tools, graphical user interfaces (GUIs), and APIs.
Types of DBMS:
- Hierarchical DBMS: Organizes data in a tree-like structure where each record has a single parent. Example: IBM’s Information Management System (IMS).
- Network DBMS: Uses a graph structure to allow more complex relationships between data entities. Example: Integrated Data Store (IDS).
- Relational DBMS (RDBMS): Organizes data in tables with rows and columns. Relationships are established using foreign keys. Example: MySQL, Oracle Database.
- Object-Oriented DBMS (OODBMS): Stores data in the form of objects, similar to object-oriented programming languages. Example: ObjectDB.
- NoSQL DBMS: Designed for unstructured or semi-structured data. Supports various data models like document, key-value, column-family, and graph. Example: MongoDB, Cassandra.
Advantages of Using a DBMS:
- Improved Data Sharing: Provides a centralized platform for multiple users to access and share data.
- Data Integrity and Accuracy: Ensures that data is consistent and accurate through integrity constraints and validation rules.
- Data Security: Protects sensitive data through authentication, authorization, and encryption.
- Efficient Data Management: Allows efficient data storage, retrieval, and manipulation using query languages.
- Scalability: Supports large volumes of data and can scale to accommodate growing data needs.
- Data Independence: Separates data structure from application logic, allowing changes to the database schema without affecting applications.
- Backup and Recovery: Provides tools for data backup and recovery to prevent data loss in case of failures.
Disadvantages of Using a DBMS:
- Complexity: DBMS can be complex to set up and manage, requiring skilled personnel and resources.
- Cost: Implementing a DBMS can be expensive, involving software licensing, hardware, and maintenance costs.
- Performance Overhead: DBMS may introduce performance overhead due to data abstraction and processing layers.
- Security Risks: A centralized database can be a target for security threats and attacks if not properly secured.
Real-Life Applications of DBMS:
- Banking Systems: Used to manage customer accounts, transactions, loans, and other financial data.
- Healthcare Management: Manages patient records, appointments, treatments, and medical inventories.
- Retail and E-Commerce: Handles product catalogs, customer data, orders, inventory, and payments.
- Education Systems: Manages student records, courses, grades, and enrollment data.
- Social Media Platforms: Stores user profiles, posts, comments, and connections.
- Government Agencies: Manages public records, census data, and other government-related information.
A DBMS plays a vital role in modern data management, providing a structured and efficient way to store, retrieve, and manipulate data across various applications and industries. Its features and capabilities make it an essential tool for organizations to manage their data effectively and securely.
Advantages and Disadvantages of DBMS
Advantages of DBMS
1. Data Redundancy Control
- Reduction of Duplicate Data: DBMS reduces redundancy by storing data in a centralized location. Data normalization techniques further minimize duplication, ensuring that each piece of information is stored only once.
2. Data Consistency
- Uniform Data Across System: By managing data centrally, DBMS ensures consistency. Any updates or changes to data are immediately reflected across all applications and users accessing the database.
3. Data Security
- Controlled Access: DBMS provides robust security features, including user authentication and authorization, ensuring that only authorized users can access or modify data.
- Data Encryption: Sensitive data can be encrypted to protect it from unauthorized access or breaches.
4. Data Integrity
- Maintaining Accuracy: Integrity constraints (such as primary keys, foreign keys, and unique constraints) are enforced, ensuring that the data stored is accurate and valid.
5. Data Independence
- Separation of Data and Applications: DBMS provides logical and physical data independence, allowing changes to the database structure without affecting application programs.
6. Efficient Data Management
- Query Optimization: DBMS uses query optimization techniques to improve the efficiency of data retrieval and manipulation.
- Advanced Data Models: Supports complex data models and relationships, making data management more efficient.
7. Data Backup and Recovery
- Automatic Backup and Recovery: DBMS provides tools for automatic data backup and recovery, ensuring data is not lost in the event of a system failure or crash.
8. Concurrent Access
- Multi-User Environment: DBMS supports multiple users accessing the database simultaneously while maintaining data consistency and integrity through concurrency control mechanisms.
9. Improved Decision Making
- Data Analysis Tools: DBMS provides powerful data analysis tools that help in generating reports and insights, aiding in better decision-making.
10. Scalability
- Handling Large Volumes of Data: DBMS can scale to handle large datasets and user loads, making it suitable for growing organizations.
11. Support for Transactions
- ACID Properties: Ensures reliable transactions through Atomicity, Consistency, Isolation, and Durability, which are critical for financial and other sensitive applications.
Disadvantages of DBMS
1. Complexity
- Setup and Management: The design, setup, and maintenance of a DBMS can be complex, requiring skilled database administrators and resources.
2. Cost
- High Initial Investment: Implementing a DBMS can be expensive due to the costs associated with software licensing, hardware, training, and ongoing maintenance.
3. Performance Overhead
- Resource Consumption: DBMS can introduce performance overhead due to its complex architecture and features like data abstraction, which might slow down simple tasks.
4. Security Risks
- Centralized Data Vulnerability: A centralized database can become a target for security threats. If not properly secured, a breach can compromise all stored data.
5. Data Migration Challenges
- Complex Migration Process: Migrating existing data to a new DBMS can be complex and time-consuming, especially if data is stored in incompatible formats.
6. Need for Regular Maintenance
- Ongoing Management Required: Regular maintenance and updates are necessary to ensure the DBMS runs efficiently and securely, requiring dedicated staff and resources.
7. Dependence on Vendors
- Vendor Lock-in: Organizations may become dependent on specific DBMS vendors, making it difficult to switch systems or negotiate pricing.
8. Potential Downtime
- System Failures: Any downtime or failure in the DBMS can lead to a loss of productivity and disruption in operations.
9. Limited Flexibility for Unstructured Data
- Structured Data Focus: Traditional DBMS may not be well-suited for handling unstructured data, requiring additional solutions for such data types.
10. Complexity of Managing Large Databases
- Difficulties in Optimization: As the database grows, it becomes more challenging to optimize performance and manage efficiently.
Conclusion
The decision to use a DBMS involves weighing its advantages against its disadvantages. While a DBMS provides a structured, secure, and efficient way to manage data, it also requires careful planning, management, and resources to implement and maintain. Organizations should consider their specific needs, data requirements, and resource availability when deciding whether to adopt a DBMS.
Database Abstraction and Data Independence
Database Abstraction
Database abstraction is a way to hide the complex details of how data is physically stored and maintained in a database, providing users with a simpler and more intuitive interface to interact with the data. This abstraction occurs at multiple levels, each offering a different perspective on the data.
Levels of Database Abstraction
The database abstraction is organized into three levels, each with its own focus and purpose:
1. Physical Level
- Definition: The physical level describes how the data is physically stored in the database. It deals with the technical details of data storage, such as file organization, indexing methods, data compression, and storage devices.
- Focus:
- Details of how data is stored on disks or other storage devices.
- Use of data structures like B-trees, hash tables, and data blocks.
- Considerations for storage optimization, retrieval speed, and storage space efficiency.
- Example:
- A database system might store customer data in a B-tree index to optimize search performance.
- Data could be compressed to save space or distributed across multiple disks for load balancing.
- Importance:
- Enables performance tuning by database administrators to optimize storage and retrieval.
- Changes at this level (e.g., moving data to a faster SSD) do not impact how users see or interact with data.
2. Logical Level
- Definition: The logical level describes what data is stored in the database and the relationships between those data. This level is concerned with the logical structure and organization of the data, focusing on the schema design and data models.
- Focus:
- Represents data in tables, views, indexes, and the relationships between them (e.g., primary and foreign keys).
- Defines data types, constraints, and rules for data integrity.
- Provides an abstract model that hides physical storage details from users and applications.
- Example:
- A table for
Studentsmight include columns likeStudentID,Name,DOB, andMajor. - Relationships between tables, such as a foreign key linking
EnrollmentstoStudents, are defined here.
- A table for
- Importance:
- Supports data independence by allowing changes to physical storage without affecting the logical structure.
- Ensures data consistency and integrity through constraints and relationships.
3. View Level
- Definition: The view level is the highest level of abstraction, providing a user-specific perspective of the database. It presents customized views of the data tailored to the needs of different users or applications.
- Focus:
- Defines user-specific views and interfaces to simplify data access and enhance security.
- Hides unnecessary details from users, presenting only the data relevant to their tasks.
- Enables different users to see the same data in different ways, depending on their needs and permissions.
- Example:
- A sales representative might have a view that shows only customer names and contact information, hiding sensitive data like financial details.
- A view for a teacher might display only student names, IDs, and grades, omitting other student details.
- Importance:
- Enhances security by restricting access to sensitive data and providing role-based access control.
- Simplifies user interaction with the database by providing intuitive and relevant data views.
Benefits of Database Abstraction
- Simplifies User Interaction: Users can interact with the database without needing to understand complex storage details.
- Improves Security: By controlling access through views, sensitive data can be protected from unauthorized access.
- Facilitates Maintenance: Changes at lower levels of abstraction do not impact users, making it easier to optimize and maintain the system.
Practical Example of Database Abstraction
Consider a hospital database system with the following abstraction levels:
- Physical Level: Patient records are stored on distributed storage arrays with indexing for fast retrieval. Data is encrypted for security.
- Logical Level: The database has tables for
Patients,Doctors, andAppointments, with relationships established using primary and foreign keys. Each table has defined constraints and data types to ensure consistency. - View Level:
- Doctors have a view that shows patient names, medical history, and current treatments.
- Administrative staff have a view with patient contact details and billing information, excluding medical data.
In this system, the complexity of how data is stored and optimized is hidden from doctors and staff, who only see the information relevant to their roles.
Data Independence
Data independence is the ability to change the database schema at one level without affecting the schema at the next higher level. It is a fundamental goal of database systems, enabling flexibility and adaptability in managing data.
Types of Data Independence
Data independence is categorized into two types, each addressing different levels of abstraction:
1. Physical Data Independence
- Definition: Physical data independence refers to the ability to change the physical storage structures or devices without affecting the logical schema or the application programs that interact with the database.
- Focus:
- Changes in physical storage do not require changes to the logical design.
- Allows administrators to optimize storage techniques, change storage devices, or reorganize data for performance improvements.
- Examples:
- Changing the storage device from traditional HDDs to faster SSDs for better performance.
- Modifying the indexing method (e.g., switching from a hash index to a B-tree) to improve query speed.
- Importance:
- Provides flexibility to adapt to technological advancements and storage optimizations.
- Reduces downtime and disruption by allowing storage changes without impacting applications.
2. Logical Data Independence
- Definition: Logical data independence is the ability to change the logical schema without altering the external schema or application programs. It focuses on changes to the logical structure, such as adding or modifying tables, columns, or relationships.
- Focus:
- Allows changes to the logical structure (e.g., schema) without affecting user interfaces and applications.
- Supports the evolution of the database to meet new business requirements or data models.
- Examples:
- Adding a new column, such as
EmailAddress, to theCustomertable without impacting existing applications. - Splitting a single
Ordertable into separateOrderandOrderDetailstables for better normalization.
- Adding a new column, such as
- Importance:
- Enables adaptation to changing business needs and requirements without costly application rewrites.
- Facilitates maintenance and evolution of the database schema to accommodate new data types and relationships.
Real-World Example of Data Independence
Consider a retail company’s database system:
- Physical Data Independence:
- The company decides to switch its database from on-premises servers to a cloud-based solution for scalability. This change involves modifying the physical storage location and structure but does not affect how users or applications interact with the data.
- Logical Data Independence:
- The company introduces a new loyalty program, requiring additional data fields in the
Customertable. New fields likeLoyaltyPointsare added without affecting existing applications that use the original fields likeCustomerIDandName.
- The company introduces a new loyalty program, requiring additional data fields in the
Importance of Data Independence
- Enhances Flexibility: Data independence allows organizations to adapt to changes in technology, business requirements, and data models without major disruptions.
- Reduces Costs: Changes can be made at specific abstraction levels without the need for extensive reprogramming, reducing development and maintenance costs.
- Improves Agility: Organizations can respond quickly to new opportunities and challenges by making necessary changes to the database without affecting users and applications.
Summary
Database abstraction and data independence are critical components of a DBMS that facilitate efficient, flexible, and secure data management.
- Database Abstraction: Provides a layered architecture that separates the physical storage details from logical and view levels, simplifying data interactions and enhancing security.
- Data Independence: Ensures that changes at one level of the database do not adversely affect other levels, promoting adaptability and reducing maintenance efforts.
Together, these concepts enable organizations to effectively manage complex data environments, optimize performance, and meet evolving business needs without compromising on security or efficiency.
Instance and Schemas
Schemas
In a DBMS, a schema refers to the design or blueprint of a database. It outlines the structure of the database, including tables and their attributes. For instance, consider an Employee table. This table might include attributes such as EMP_ID, EMP_ADDRESS, EMP_NAME, and EMP_CONTACT. These attributes collectively define the schema of the Employee table.
Schemas can be categorized into three main types:
- Logical Schema: Represents the logical structure of the database, including tables, relationships, and constraints. It defines what data is stored and how it is organized, without concern for how the data is physically stored.
- View Schema: Provides user-specific views or perspectives of the data, often tailored to specific applications or user roles. These views help in simplifying data access and enhancing security by restricting access to sensitive information.
- Physical Schema: Describes how data is physically stored in the database, detailing storage structures, indexes, and access methods. It is concerned with the optimization of data storage and retrieval.
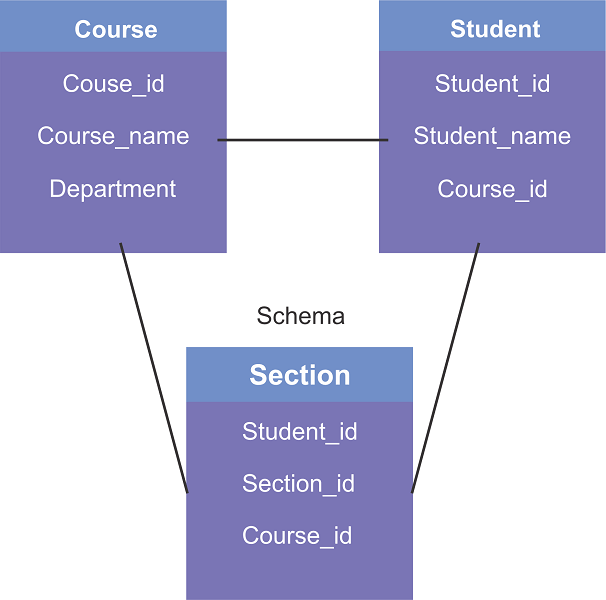
The schema defines the logical view of the database, providing essential information about how data is organized and where it needs to go. In DBMS, schemas are often represented in diagram format, which helps visualize the relationships between different data elements in the database.
Understanding the schema is crucial for implementing various DBMS functions, such as inserting, deleting, searching, and updating data. For example, a diagram illustrating the relationships between Section, Course, and Student tables helps clarify how these entities are connected and how operations can be performed across them.
In summary
a schema is a structural blueprint of a database, providing a comprehensive view of its design and how data is related. It serves as the foundation for database management and operations.
Instance
The data is stored for a particular amount of time and is called an instance of the database. The database schema defines the attributes of the database in the particular DBMS. The value of the particular attribute at a particular moment in time is known as an instance of the DBMS.
Characteristics of an Instance
- Dynamic: Unlike schemas, instances are dynamic and change frequently as data is inserted, updated, or deleted.
- Current State: An instance reflects the current state of the database, capturing the real-time data at any given moment.
- Data Content: Instances contain the actual data entries in the tables defined by the schema.
Example of an Instance
Continuing with the library database example, an instance might look like this:
Instance of Books Table
| BookID | Title | Author | Genre | PublishedYear |
|---|---|---|---|---|
| 1 | The Great Gatsby | F. Scott Fitzgerald | Fiction | 1925 |
| 2 | To Kill a Mockingbird | Harper Lee | Fiction | 1960 |
| 3 | 1984 | George Orwell | Dystopian | 1949 |
Instance of Members Table
| MemberID | Name | Address | |
|---|---|---|---|
| 101 | bhanu | 123 Maple St. | bhanu@example.com |
| 102 | yaswantha | 456 Oak Ave. | prakash@example.com |
| 103 | akhil | 789 Pine Rd. | charlie@example.com |
Instance of Borrowing Table
| BorrowID | MemberID | BookID | BorrowDate | ReturnDate |
|---|---|---|---|---|
| 201 | 101 | 1 | 2024-07-01 | 2024-07-15 |
| 202 | 102 | 3 | 2024-07-03 | 2024-07-17 |
| 203 | 101 | 2 | 2024-07-05 | NULL |
Explanation:
- Data Entries: The instance includes actual data entries in each table, such as specific books, members, and borrowing transactions.
- Changes Over Time: As new books are added, members are registered, or borrowing records are updated, the instance will change accordingly.
Importance of Instances
- Real-Time Data: Instances provide a real-time view of the data, allowing applications and users to interact with the current state of the database.
- Operational Use: Instances are used for operational tasks, such as querying, updating, and reporting on current data.
- Testing and Development: Instances can be used in testing and development to simulate real-world data scenarios.
Relationship Between Schema and Instance
The relationship between a schema and an instance can be likened to the relationship between a blueprint and a building:
- Schema as Blueprint: The schema serves as a blueprint or design for the database, defining its structure and rules. It remains relatively stable and changes infrequently.
- Instance as Building: The instance is akin to the actual building constructed based on the blueprint. It is dynamic and changes as the database is used and modified.
Key Differences
| Aspect | Schema | Instance |
|---|---|---|
| Nature | Static (design and structure) | Dynamic (actual data) |
| Frequency of Change | Infrequent | Frequent (as data changes) |
| Content | Metadata (tables, relationships) | Actual data entries |
| Purpose | Design, integrity, and security | Operational data use |
Examples of Schema and Instance Changes
- Schema Change:
- Adding a new table for
Authorswith columns forAuthorIDandBiography. - Modifying a column data type, such as changing
EmailfromVARCHAR(50)toVARCHAR(100).
- Adding a new table for
- Instance Change:
- Adding a new book entry in the
Bookstable. - Updating a member’s address in the
Memberstable. - Deleting a borrowing record from the
Borrowingtable.
- Adding a new book entry in the
Conclusion
Understanding the distinction between schemas and instances is crucial for effective database management:
- Schemas provide the structural framework and rules for the database, ensuring data consistency, integrity, and security.
- Instances represent the real-time data stored in the database, enabling operational tasks, reporting, and user interactions.
By maintaining clear schemas and managing dynamic instances, database administrators can ensure the reliability, performance, and adaptability of a database system.
Data Models
Data models are abstract frameworks used to define and structure data in a database. They provide a conceptual representation of how data is organized, stored, and managed. Data models help ensure that the database is designed efficiently, supports data integrity, and meets user requirements.
Classification of Data model
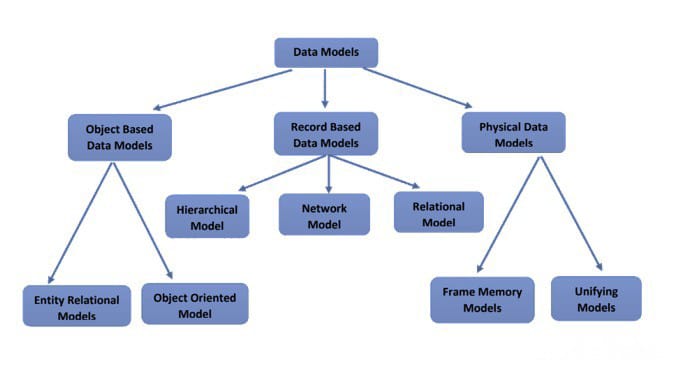
Object-Based Data Model
The Object-Based Data Model integrates principles from object-oriented programming with database management. It represents data as objects, similar to how objects are handled in programming languages like Java or C++. This model aims to capture complex relationships and behaviors associated with data.
Characteristics
- Objects and Classes: Data is represented as objects, which are instances of classes. Each object contains attributes (data fields) and methods (functions or procedures).
- Encapsulation: Objects encapsulate data and behavior, allowing for a modular and reusable design.
- Inheritance: Supports inheritance, where a class can inherit properties and methods from another class.
- Polymorphism: Objects can be manipulated through a common interface, even if they are of different classes.
Example
Consider an object-based model for a university database:
- Class:
Person- Attributes:
name,address,email - Methods:
updateAddress(),sendEmail()
- Attributes:
- Class:
Student(inherits fromPerson)- Attributes:
studentID,major - Methods:
enrollCourse(),dropCourse()
- Attributes:
- Class:
Professor(inherits fromPerson)- Attributes:
employeeID,department - Methods:
assignGrade(),scheduleOfficeHours()
- Attributes:
In this model, Student and Professor are specialized types of Person, inheriting common attributes and methods while adding their own specific properties and behaviors.
Benefits
- Complex Data Relationships: Handles complex data relationships and behaviors naturally.
- Modularity: Supports modular design, making it easier to manage and extend the database.
- Code Reusability: Encourages reuse of code and design through inheritance and polymorphism.
Usage
- Applications: Suitable for applications requiring complex data models and object-oriented design, such as multimedia systems and computer-aided design (CAD) applications.
Record-Based Data Model
The Record-Based Data Model organizes data into fixed-format records, which are structured and typically organized into tables. This model is used in relational databases and has a more rigid structure compared to object-based models.
Characteristics
- Records: Data is represented as records (rows) within tables. Each record contains a fixed set of fields (columns).
- Schemas: The schema defines the structure of tables, including columns, data types, and constraints.
- Fixed Format: Each record has a fixed format, making it easy to manage and query data.
Example
Consider a relational database for an employee management system:
- Table:
Employee- Columns:
EMP_ID,EMP_NAME,EMP_ADDRESS,EMP_CONTACT - Record:
EMP_ID: 1EMP_NAME: John DoeEMP_ADDRESS: 123 Elm StEMP_CONTACT: 555-1234
- Columns:
In this model, each row in the Employee table represents a single record with predefined columns.
Benefits
- Simplicity: Simple and straightforward data organization, making it easy to understand and manage.
- Efficient Querying: Relational databases use SQL for querying, which is powerful and well-supported.
- Data Integrity: Enforces data integrity through constraints and relationships.
Usage
- Applications: Widely used in relational databases (e.g., MySQL, Oracle) for business applications, data warehousing, and transaction processing.
Physical-Based Data Model
The Physical-Based Data Model focuses on how data is physically stored in the database. It deals with the specifics of data storage, indexing, and performance optimization.
Characteristics
- Storage Structures: Defines how data is stored on physical media (e.g., disks, SSDs), including data files, indexes, and access paths.
- Indexing: Implements indexing methods to optimize data retrieval and query performance.
- Optimization: Involves techniques for optimizing storage space and retrieval speed, such as data compression and partitioning.
Example
Consider the physical storage of an employee database:
- Storage File:
employee_data.dat - Index:
emp_id_index.idx(B-tree index onEMP_ID) - Compression: Data is compressed to save storage space.
In this model, the physical layout of the data, indexing strategies, and storage optimization techniques are defined to ensure efficient performance and management.
Benefits
- Performance Optimization: Enhances database performance through efficient data storage and retrieval techniques.
- Resource Management: Manages resources such as disk space and I/O operations effectively.
- Adaptability: Allows for adaptation to different hardware and storage technologies.
Usage
- Applications: Important for database administrators and system designers who focus on performance tuning, storage management, and system configuration.
Summary
Data Models Overview
- Object-Based Data Model: Represents data as objects with attributes and methods, supporting complex relationships and behaviors.
- Record-Based Data Model: Organizes data into fixed-format records and tables, used in relational databases for structured data management.
- Physical-Based Data Model: Focuses on the physical storage and optimization of data, including indexing and performance tuning.
1.Entity Relationship Model(ER Model)
The Entity-Relationship (ER) Model is a conceptual framework used to design and represent the structure of a database. It provides a high-level view of the data and the relationships between different data entities. The ER model is widely used in database design and helps in visualizing and documenting the data requirements of a system.
Key Concepts of the ER Model
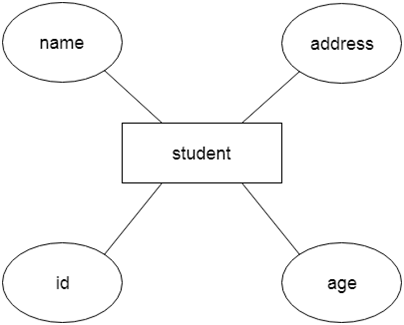
Entities: Entities represent objects or concepts in the real world that have a distinct existence within the database. Each entity has attributes that describe its properties.
an example- manager, product, employee, department etc. can be taken as an entity.

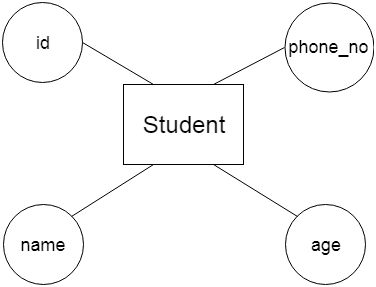
Attributes: Attributes are properties or characteristics of an entity. They provide more detail about the entity and can be simple or composite.
For example, id, age, contact number, name, etc. can be attributes of a student.
Entity Sets: An entity set is a collection of similar types of entities. For example, the set of all Students in a university is an entity set.
Relationships: Relationships describe how entities interact with each other. They represent associations between two or more entities.

Relationship Example: A Teachers relationship might link Student entities to teacher entities, indicating which students are enrolled in which courses.
Relationship Sets: A relationship set is a collection of similar relationships. For example, the set of all Registration relationships in the database is a relationship set.
Keys: Keys are attributes that uniquely identify an entity within an entity set. The primary key is the main attribute used to uniquely identify each record.
Key Example: In the Student entity set, StudentID might be the primary key.
Cardinality: Cardinality specifies the number of instances of one entity that can or must be associated with instances of another entity. Common cardinality types are one-to-one (1:1), one-to-many (1), and many-to-many (M).
Cardinality Example: A Professor can teach multiple Courses, and each Course can be taught by multiple Professors (Many-to-Many relationship).
ER Diagram Components
ER diagrams visually represent the ER model and include the following components:
- Entities: Represented by rectangles. Each entity is labeled with its name.
- Example: A rectangle labeled
Student.
- Example: A rectangle labeled
- Attributes: Represented by ovals connected to their respective entities. Attributes are labeled with their names.
- Example: An oval labeled
StudentIDconnected to theStudentrectangle.
- Example: An oval labeled
- Relationships: Represented by diamonds connected to the entities involved in the relationship. Relationships are labeled with their names.
- Example: A diamond labeled
EnrollsconnectingStudentandCourserectangles.
- Example: A diamond labeled
- Cardinality Notations: Indicate the nature of the relationships, often shown as numbers or symbols near the entity rectangles.
- Example: A line connecting
StudenttoCoursewith a notation ofNnearCourseindicating many students can enroll in many courses.
- Example: A line connecting
Example of an ER Diagram
Consider a simple ER diagram for a university database:
- Entities:
Student,Course,Professor - Attributes:
Student:StudentID,Name,MajorCourse:CourseID,CourseName,CreditsProfessor:ProfessorID,Name,Department
- Relationships:
Enrolls: ConnectsStudenttoCourse(Many-to-Many)Teaches: ConnectsProfessortoCourse(Many-to-Many)
Diagram:
plaintext [Student] -------- Enrolls -------- [Course]
| |
| |
[StudentID] [CourseID]
[Name] [CourseName]
[Major] [Credits]
|
|
[Teaches]
|
|
[Professor]
[ProfessorID]
[Name]
[Department]
Another example, Suppose we design a school database. In this database, the student will be an entity with attributes like address, name, id, age, etc. The address can be another entity with attributes like city, street name, pin code, etc and there will be a relationship between them.
Advantages of the ER Model
- Clarity: Provides a clear and intuitive representation of the data structure and relationships.
- Design Tool: Serves as a blueprint for designing database schemas, making it easier to translate the conceptual model into a physical database.
- Communication: Facilitates communication between database designers, developers, and stakeholders by providing a visual representation of the data.
Limitations of the ER Model
- Complexity: For large and complex databases, ER diagrams can become cluttered and hard to manage.
- Abstract Nature: The ER model is a high-level representation and does not address implementation details such as indexing or performance optimization.
Summary
The Entity-Relationship (ER) Model is a fundamental tool in database design that provides a conceptual framework for representing and organizing data. By using entities, attributes, and relationships, ER diagrams help visualize the structure of a database and facilitate the development of a well-organized and efficient database schema.
2.Hierarchial Data Model
The Hierarchical Data Model is one of the earliest data models used in database management systems. It organizes data in a tree-like structure, where each data element has a single parent and potentially multiple children. This model is designed to represent data with a clear hierarchical relationship.
Key Features of the Hierarchical Data Model
- Tree Structure: The data is organized in a tree-like structure, with a single root node at the top and various levels of child nodes beneath it. Each node represents a data record.
- Parent-Child Relationship: Each node (or record) has a single parent, and can have multiple child nodes. This represents a one-to-many relationship between nodes.
- Hierarchical Path: Data retrieval requires navigating from the root node down to the desired child nodes, following a path defined by parent-child relationships.
- Fixed Structure: The structure of the hierarchy is fixed and predefined. Any changes to the hierarchy, such as adding new levels or relationships, often require significant restructuring.
Example of the Hierarchical Data Model
Consider an organizational structure of a company:
- Root Node:
Company- Child Node:
Department- Child Node:
Employee - Child Node:
Employee
- Child Node:
- Child Node:
Department- Child Node:
Employee - Child Node:
Employee
- Child Node:
- Child Node:
In this example:
Companyis the root node.Departmentnodes are children of theCompanynode.Employeenodes are children of theDepartmentnodes.
Diagram Representation
A hierarchical data model is often represented using a tree diagram. Here’s a simplified diagram of the organizational example:
markdownCopy code Company
/ \
Department Department
/ \ / \
Employee Employee Employee Employee

Advantages of the Hierarchical Data Model
- Simple Structure: Easy to understand and implement for data with a clear hierarchical relationship.
- Efficient Data Access: Efficient for queries that follow the hierarchy, such as retrieving all employees in a specific department.
- Data Integrity: Enforces data integrity through parent-child relationships, ensuring that data is consistent within the hierarchy.
Disadvantages of the Hierarchical Data Model
- Rigid Structure: Limited flexibility; changes in the hierarchy often require restructuring the entire database.
- Complex Relationships: Difficult to represent many-to-many relationships, as each node has only one parent.
- Navigation Complexity: Navigating the hierarchy can be cumbersome, especially for complex data structures with multiple levels.
Use Cases
- Early Database Systems: Historically used in early database management systems like IBM’s Information Management System (IMS).
- Organizational Structures: Suitable for representing organizational hierarchies, file systems, and directory structures.
Summary
The Hierarchical Data Model organizes data into a tree-like structure with parent-child relationships. It is straightforward and efficient for hierarchical data but has limitations in flexibility and handling complex relationships. While less common in modern database systems, it provides a foundational understanding of data organization and management.
Network model

Advantages of the Network Model
- Flexibility: The network model allows complex many-to-many relationships, making it more flexible than hierarchical models.
- Efficiency: It provides faster access to data due to its direct relationship between records.
- Data Integrity: The use of set structures (or relationships) enforces integrity by ensuring that records are connected correctly.
- Navigational: It allows easy traversal through records and relationships using navigational pointers.
- Supports Redundancy: It can handle redundant data more gracefully compared to other models.
Disadvantages of the Network Model
- Complexity: The structure can become complicated and difficult to design and maintain, especially for large databases.
- Navigational Burden: Users must understand the database’s structure to navigate through it effectively.
- Lack of Structural Independence: Changes in the structure (e.g., adding a new relationship) require modifications in the application code.
- Difficult Implementation: It requires complex algorithms to manage connections and pointers, making it harder to implement than simpler models.
- Limited Support: Modern DBMS systems do not widely use the network model as much as relational models.
Use Cases
Despite its complexity, the network model can be useful in scenarios where the relationships between entities are inherently many-to-many, such as:
- Telecommunications networks: Managing connections and pathways.
- Transportation networks: Routing and logistics planning.
- Organizational structures: Representing complex employee hierarchies and reporting lines.
The network model provides an efficient way to manage complex relationships and data structures but at the cost of increased complexity and navigational challenges. Modern databases often use relational models, which offer better support and ease of use, but the network model remains an important part of the history and evolution of database systems.
Relational Model
The relational model is a popular and widely used data model in database management systems (DBMS). It organizes data into tables (also called relations) consisting of rows and columns, where each row represents a unique record and each column represents an attribute of the data.
Advantages of the Relational Model
- Simplicity: The relational model is easy to understand and use due to its tabular structure.
- Data Integrity: Constraints like primary keys and foreign keys help maintain data accuracy and integrity.
- Flexibility: The relational model allows for easy querying and manipulation of data using SQL (Structured Query Language).
- Normalization: The process of organizing data to minimize redundancy and dependency, improving data integrity.
- Data Independence: Changes to the data structure do not require changes to the applications that access the data.
- Scalability: Relational databases can handle large volumes of data and complex queries efficiently.
Disadvantages of the Relational Model
- Complexity for Large Datasets: As the volume of data grows, performance can become an issue, requiring optimization techniques.
- Rigid Schema: Changes to the database schema can be complex and require downtime.
- Performance Overhead: Joins between tables can be computationally expensive, affecting performance.
- Limited Support for Unstructured Data: Relational databases are less suited for handling unstructured or semi-structured data compared to NoSQL databases.
Use Cases
The relational model is widely used in various applications, including:
- Business Applications: Managing customer data, orders, and transactions.
- Financial Systems: Handling complex financial records and transactions.
- Human Resources: Managing employee records, payroll, and benefits.
- E-commerce: Handling product catalogs, customer orders, and inventory.
The relational model’s simplicity, flexibility, and support for SQL make it a popular choice for a wide range of applications. It has become the foundation for many modern database systems, such as MySQL, PostgreSQL, Oracle, and Microsoft SQL Server.
Example Tables
Let’s illustrate the relational model with a simple example of employee and department tables:
Employee Table:
| EmployeeID | Name | DepartmentID |
|---|---|---|
| 1 | Bhanu | 101 |
| 2 | Alice | 102 |
| 3 | Bob | 101 |
| 4 | Charlie | 103 |
Department Table:
| DepartmentID | DepartmentName |
|---|---|
| 101 | IT |
| 102 | HR |
| 103 | Finance |
In this example:
- The EmployeeID in the Employee table is a primary key.
- The DepartmentID in the Department table is a primary key.
- The DepartmentID in the Employee table is a foreign key referencing the Department table.
These tables can be queried and joined to retrieve information, such as finding all employees in a specific department:
SELECT e.Name, d.DepartmentName
FROM Employee e
JOIN Department d ON e.DepartmentID = d.DepartmentID
WHERE d.DepartmentName = 'IT';
This query retrieves the names of employees in the IT department, demonstrating the power and flexibility of the relational model in handling and querying data.
Database Languages DDL,DML,TCL
In database management systems (DBMS), database languages are used to define, manipulate, control, and query data. The primary categories of database languages are:
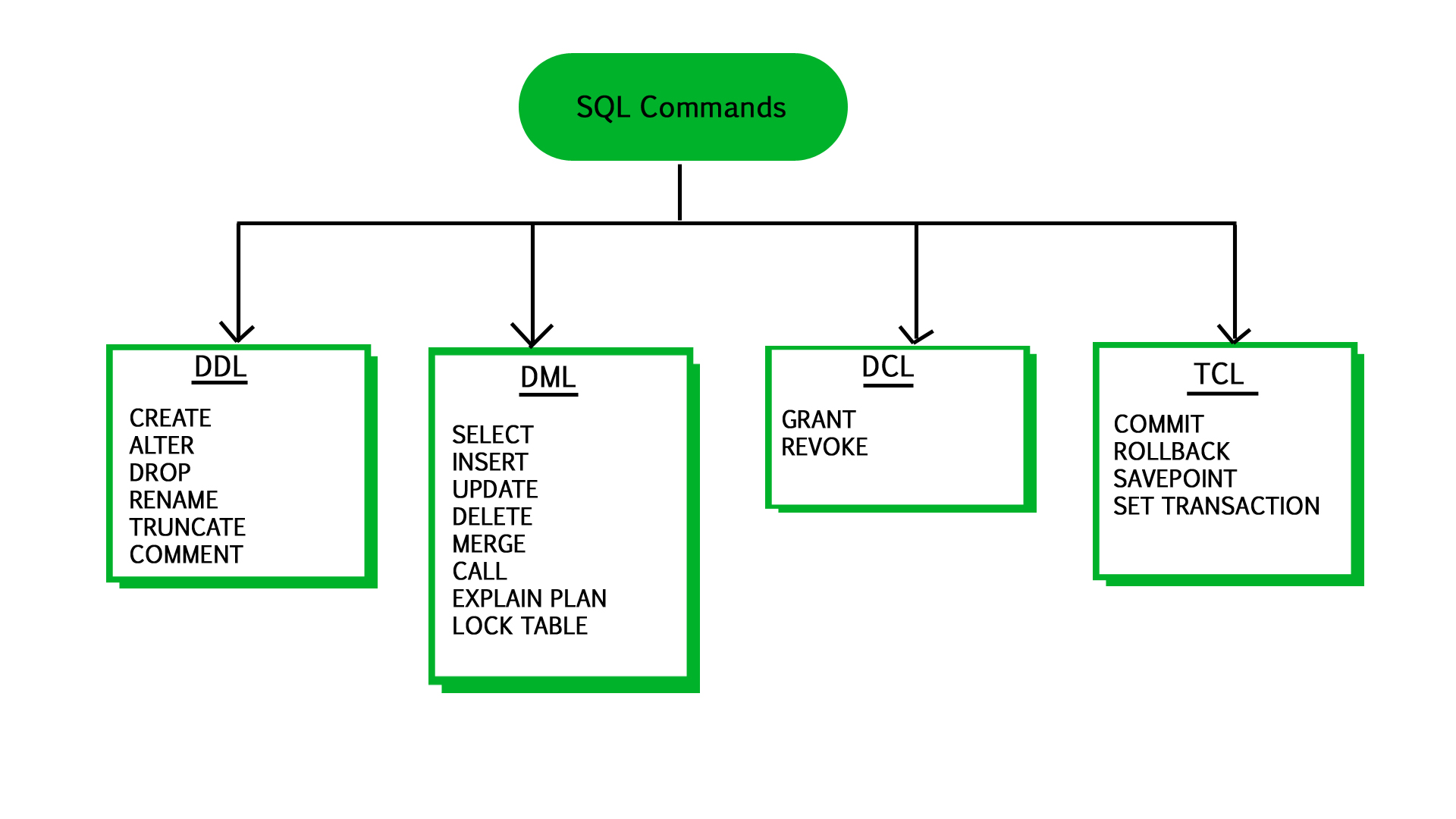
- Data Definition Language (DDL)
- Data Manipulation Language (DML)
- Transaction Control Language (TCL)
- Data Control Language (DCL)
Data Definition Language (DDL)
DDL is used to define and manage database schemas and structures. It includes commands for creating, altering, and deleting database objects such as tables, indexes, and views.
Common DDL Commands
CREATE: Used to create database objects such as tables, indexes, and views.
CREATE TABLE Employees (
EmployeeID INT PRIMARY KEY,
Name VARCHAR(50),
DepartmentID INT,
Salary DECIMAL(10, 2)
);2. ALTER: Used to modify existing database objects, such as adding or dropping columns in a table.
ALTER TABLE Employees
ADD DateOfBirth DATE;3.DROP: Used to delete database objects such as tables, indexes, or views.
DROP TABLE bhanu1;4.TRUNCATE: Used to remove all records from a table, resetting it to its initial state, but maintaining its structure.
TRUNCATE TABLE bhanu1;5.RENAME: Used to rename database objects.
RENAME TABLE bhanu1 TO bhanu2;Data Manipulation Language (DML)
DML is used to manipulate and retrieve data within existing database objects. It includes commands for inserting, updating, deleting, and querying data.
Common DML Commands:
1.SELECT: Used to query and retrieve data from tables.
SELECT Name, DepartmentID FROM bhanu2 WHERE Salary > 50000;2.INSERT: Used to add new records to a table.
INSERT INTO bhanu2 (EmployeeID, Name, DepartmentID, Salary)
VALUES (1, 'Bhanu', 101, 60000);3.UPDATE: Used to modify existing records in a table.
UPDATE Employees
SET Salary = 65000
WHERE EmployeeID = 1;4.DELETE: Used to remove records from a table.
DELETE FROM Employees WHERE EmployeeID = 1;Transaction Control Language (TCL)
TCL is used to manage transactions within a database, ensuring data integrity and consistency. It includes commands for committing, rolling back, and saving changes.
Common TCL Commands:
1.COMMIT: Used to permanently save all changes made during a transaction.
COMMIT;2.ROLLBACK: Used to undo changes made during the current transaction, reverting the database to its previous state.
ROLLBACK;3.SAVEPOINT: Used to set a savepoint within a transaction, allowing partial rollback to that point
SAVEPOINT Savepoint1;4.RELEASE SAVEPOINT: Used to remove a savepoint, releasing resources associated with it.
RELEASE SAVEPOINT Savepoint1;5.SET TRANSACTION: Used to set the properties for a transaction, such as isolation level.
SET TRANSACTION READ ONLY;Database Administrator(DBA)
A Database Administrator (DBA) is a key role within an organization responsible for managing, maintaining, and securing the database systems that store and organize an organization’s data. DBAs ensure that databases operate efficiently and are accessible to users and applications when needed.
Roles and Responsibilities of a Database Administrator
- Database Installation and Configuration:
- Install and configure new database systems.
- Set up the database environment to meet organizational requirements.
- Database Design:
- Design and implement database schemas and structures.
- Ensure that database designs meet data integrity and performance requirements.
- Performance Monitoring and Tuning:
- Monitor database performance and optimize queries for efficiency.
- Identify and resolve performance bottlenecks.
- Data Security and Access Control:
- Implement security measures to protect sensitive data.
- Manage user permissions and access controls to ensure data privacy and integrity.
- Backup and Recovery:
- Develop and implement backup and recovery strategies.
- Perform regular backups and ensure that data can be restored in case of data loss or corruption.
- Database Maintenance:
- Perform routine maintenance tasks such as updating statistics and rebuilding indexes.
- Manage data storage and disk space utilization.
- Troubleshooting and Problem Resolution:
- Diagnose and resolve database-related issues.
- Provide support to application developers and end-users.
Types of Database administrator
Database Administrators (DBAs) specialize in various aspects of database management to meet the specific needs of organizations. Depending on the focus area, DBAs can be categorized into several types, each with its own set of responsibilities and skills. Here are the common types of DBAs:
1. System DBA
- Focus: Manages the physical aspects of database management systems.
- Responsibilities:
- Install and configure database software and updates.
- Manage database storage structures and disk space.
- Monitor and optimize server performance.
- Handle system-level backups and recovery.
- Manage hardware and operating system configurations related to the database.
- Skills:
- In-depth knowledge of operating systems and hardware.
- Experience with database installation and configuration.
- Strong understanding of performance tuning and optimization.
2. Database Architect
- Focus: Design and structure databases to meet organizational needs.
- Responsibilities:
- Design database schemas and structures for optimal performance.
- Define data models and relationships between data entities.
- Establish data standards and guidelines.
- Collaborate with developers and stakeholders to design databases that meet application requirements.
- Skills:
- Strong knowledge of database design principles and modeling.
- Experience with data modeling tools and techniques.
- Ability to translate business requirements into technical specifications.
3. Application DBA
- Focus: Works with application developers to optimize and maintain databases for specific applications.
- Responsibilities:
- Optimize database queries and indexing strategies.
- Support developers with database design and query optimization.
- Ensure database performance and availability for applications.
- Implement application-level data security and integrity measures.
- Skills:
- Proficiency in SQL and application development languages.
- Strong problem-solving and analytical skills.
- Experience with query optimization and performance tuning.
4. Development DBA
- Focus: Supports database development and ensures efficient database usage.
- Responsibilities:
- Collaborate with development teams to design and implement databases.
- Optimize database code, queries, and stored procedures.
- Ensure that databases meet development and application needs.
- Participate in software development lifecycle (SDLC) activities.
- Skills:
- Strong programming and development skills.
- Experience with database development tools and environments.
- Knowledge of version control and software development methodologies.
5. Data Warehouse DBA
- Focus: Manages data warehouses and supports business intelligence (BI) activities.
- Responsibilities:
- Design and implement data warehouse schemas and structures.
- Manage ETL (Extract, Transform, Load) processes to populate data warehouses.
- Optimize data warehouse performance for reporting and analysis.
- Support BI and analytics teams with data access and queries.
- Skills:
- Knowledge of data warehousing concepts and architectures.
- Experience with ETL tools and processes.
- Strong understanding of BI and analytics requirements.
6. Cloud DBA
- Focus: Manages databases hosted on cloud platforms.
- Responsibilities:
- Deploy and manage databases in cloud environments (e.g., AWS, Azure, Google Cloud).
- Monitor cloud database performance and scalability.
- Implement cloud-specific security and backup strategies.
- Optimize resource utilization and cost management in the cloud.
- Skills:
- Familiarity with cloud platforms and services.
- Experience with cloud-based database technologies (e.g., Amazon RDS, Azure SQL Database).
- Knowledge of cloud security and compliance practices.
7. Operational DBA
- Focus: Ensures the day-to-day operation and maintenance of databases.
- Responsibilities:
- Perform routine database maintenance tasks.
- Monitor database performance and troubleshoot issues.
- Manage user access and permissions.
- Perform regular backups and ensure data recovery.
- Skills:
- Strong understanding of database administration best practices.
- Experience with database monitoring and maintenance tools.
- Proficiency in database security and access control.
8. Security DBA
- Focus: Focuses on database security and compliance.
- Responsibilities:
- Implement security measures to protect sensitive data.
- Manage database access controls and permissions.
- Ensure compliance with data protection regulations (e.g., GDPR, HIPAA).
- Monitor for security breaches and vulnerabilities.
- Skills:
- Strong knowledge of security best practices and standards.
- Experience with encryption and authentication technologies.
- Familiarity with regulatory compliance requirements.
9. Performance DBA
- Focus: Specializes in optimizing database performance.
- Responsibilities:
- Monitor and analyze database performance metrics.
- Identify and resolve performance bottlenecks.
- Optimize queries, indexes, and database configurations.
- Implement caching and other performance-enhancing techniques.
- Skills:
- Expertise in performance tuning and optimization.
- Proficiency in monitoring tools and techniques.
- Strong analytical and problem-solving skills.
Conclusion
Each type of DBA plays a crucial role in ensuring the efficient, secure, and reliable operation of database systems. Organizations may have one or more types of DBAs depending on their specific needs and the complexity of their database environments. By specializing in different aspects of database management, DBAs can focus on their areas of expertise and contribute to the overall success of the organization’s data strategy.
Importance of Database Administrator
The role of a Database Administrator (DBA) is crucial in ensuring that an organization’s data infrastructure operates smoothly and efficiently. As businesses increasingly rely on data to drive decision-making, the importance of having skilled DBAs becomes even more pronounced. Here are some key reasons why DBAs are vital to organizations:
1. Ensuring Data Availability and Reliability
- 24/7 Uptime: DBAs ensure that databases are available around the clock, minimizing downtime and ensuring that applications and users can access data when needed.
- High Availability: Implementing solutions like clustering and replication to ensure continuous availability and failover support in case of server failures.
2. Data Integrity and Security
- Data Accuracy: DBAs enforce data integrity constraints to ensure that the data stored in databases is accurate and consistent.
- Security Measures: Implementing robust security measures to protect sensitive data from unauthorized access, breaches, and cyberattacks.
3. Performance Optimization
- Query Tuning: Optimizing queries and indexes to improve database performance and reduce response times for data retrieval.
- Resource Management: Efficiently managing system resources to ensure optimal database performance, especially under high load conditions.
4. Backup and Recovery
- Data Protection: Regularly backing up data to prevent loss due to hardware failures, human errors, or other disasters.
- Disaster Recovery: Developing and testing disaster recovery plans to ensure data can be quickly restored in case of an unexpected event.
5. Database Design and Implementation
- Schema Design: Designing database schemas that support organizational requirements and business logic.
- Scalability: Planning and implementing database systems that can scale with the growth of data and users.
Conclusion
Database Administrators are integral to the success of an organization by ensuring that data is available, secure, and efficiently managed. They play a vital role in maintaining the backbone of an organization’s data infrastructure, allowing businesses to leverage data effectively for strategic decision-making and operational excellence. As data continues to grow in importance, the role of DBAs becomes even more critical in driving organizational success.
Role and Duties of Database Administrator
The role of a Database Administrator (DBA) is multifaceted and vital to the smooth operation and success of an organization’s database systems. DBAs are responsible for the design, implementation, maintenance, and security of databases, ensuring that they are reliable, efficient, and accessible to users and applications. Here are the primary roles and duties of a DBA:
Roles of a Database Administrator
- Database Designer
- Design and structure databases to meet organizational and application requirements.
- Develop data models and schemas that support business processes and logic.
- Database Implementer
- Install and configure database management systems (DBMS) software.
- Set up database environments for development, testing, and production.
- Database Operator
- Monitor and maintain database systems for optimal performance and reliability.
- Ensure high availability and uptime for critical databases.
- Data Security Manager
- Implement security measures to protect sensitive data.
- Manage user access controls and permissions to ensure data privacy and integrity.
- Backup and Recovery Specialist
- Develop and implement backup and recovery strategies to prevent data loss.
- Perform regular backups and test recovery procedures for reliability.
- Support and Troubleshooting Expert
- Provide technical support and assistance to users and application developers.
- Diagnose and resolve database-related issues and problems.
Duties of a Database Administrator
1. Database Design and Architecture
- Schema Design: Create and manage database schemas that align with business requirements and data models.
- Data Modeling: Develop logical and physical data models to represent data structures and relationships.
- Normalization: Ensure data is organized and stored efficiently, minimizing redundancy and dependency.
2. Database Installation and Configuration
- Software Installation: Install and configure DBMS software and related tools.
- Environment Setup: Set up development, testing, and production environments for database operations.
- Version Management: Manage database versions and apply patches and updates as needed.
3. Database Maintenance and Monitoring
- Performance Monitoring: Continuously monitor database performance using tools and metrics to identify issues.
- Maintenance Tasks: Perform routine maintenance tasks such as updating statistics, rebuilding indexes, and defragmenting data.
- Resource Management: Manage disk space, memory, and CPU resources to ensure optimal database performance.
4. Data Security and Access Control
- Access Management: Define and manage user roles, permissions, and access controls to protect sensitive data.
- Encryption: Implement encryption for data at rest and in transit to enhance security.
- Security Audits: Conduct regular security audits to identify vulnerabilities and ensure compliance.
5. Backup and Recovery Management
- Backup Planning: Develop and implement backup strategies to ensure data availability and protection.
- Recovery Testing: Regularly test recovery procedures to verify their effectiveness and reliability.
- Disaster Recovery: Implement disaster recovery plans to minimize downtime and data loss in case of failures.
Database Users
In a database management system (DBMS), various types of users interact with the database, each with different roles and responsibilities. These users range from those who design and manage the database to those who interact with it on a daily basis for various business functions. Here’s a detailed look at the types of database users:
1. Database Administrators (DBAs)
- Role: Responsible for the overall management of the database system.
- Responsibilities:
- Install, configure, and maintain the DBMS.
- Design database schemas and manage data storage.
- Ensure database security, backup, and recovery.
- Monitor and optimize database performance.
- Manage user permissions and access controls.
2. Database Designers
- Role: Responsible for designing the database structure.
- Responsibilities:
- Create data models and define the relationships between data entities.
- Design database schemas, tables, indexes, and views.
- Ensure data integrity and normalization.
- Collaborate with developers and business analysts to meet application requirements.
3. Application Developers
- Role: Develop applications that interact with the database.
- Responsibilities:
- Write SQL queries and procedures to retrieve and manipulate data.
- Integrate database operations into application code.
- Optimize database access for performance and efficiency.
- Collaborate with DBAs and database designers to ensure compatibility and performance.
4. End Users
- Role: Use applications that interact with the database for various business functions.
- Responsibilities:
- Perform data entry, updates, and queries through application interfaces.
- Generate reports and analyze data using application tools.
- Follow best practices and guidelines for data usage and security.
- Types of End Users:
- Casual Users: Occasionally interact with the database, often through GUI-based applications.
- Parametric Users: Regularly perform routine operations, often using predefined queries and forms (e.g., bank tellers, clerks).
- Power Users: Have a deeper understanding of the database and perform complex queries and analysis (e.g., business analysts).
5. Data Analysts and Scientists
- Role: Analyze and interpret data stored in the database to support decision-making.
- Responsibilities:
- Perform complex queries and data mining.
- Use statistical and analytical tools to derive insights from data.
- Create visualizations and reports to present findings.
- Collaborate with other departments to understand data needs and provide solutions.
6. System Analysts
- Role: Bridge the gap between business needs and technology solutions.
- Responsibilities:
- Analyze business processes and determine data requirements.
- Work with database designers and developers to implement database solutions.
- Ensure that database systems meet business requirements and improve efficiency.
- Provide specifications and requirements for database design and functionality.
7. Information Security Analysts
- Role: Ensure the security and integrity of the database.
- Responsibilities:
- Implement and enforce database security policies.
- Monitor database activities for suspicious behavior.
- Conduct security audits and vulnerability assessments.
- Ensure compliance with data protection regulations and standards.
8. Database Testers
- Role: Test the database and related applications to ensure functionality and performance.
- Responsibilities:
- Develop test plans and cases for database systems.
- Perform data validation and integrity checks.
- Test database performance and scalability.
- Report and track defects, working with developers to resolve issues.
9. Managers and Executives
- Role: Use high-level reports and data insights for strategic decision-making.
- Responsibilities:
- Access summarized and aggregated data through dashboards and reports.
- Use data insights to make informed business decisions.
- Request custom reports and analyses from data analysts and DBAs.
- Ensure that data-driven strategies align with organizational goals.
10. Technical Support Staff
- Role: Provide support and troubleshooting for database-related issues.
- Responsibilities:
- Assist end users with database access and usage problems.
- Troubleshoot and resolve technical issues related to database applications.
- Work with DBAs and developers to address and fix database problems.
- Provide training and documentation for users.
Conclusion
Each type of database user plays a crucial role in the effective management and utilization of database systems. From designing and maintaining the database to using it for day-to-day operations and strategic decision-making, the collaboration of all these users ensures that the database supports the organization’s goals efficiently and securely. Understanding the different roles and responsibilities helps in designing better database systems and improving overall data management practices.
Database System Architecture
Database System Architecture refers to the design and structure of a database management system (DBMS) and the way it interacts with various components to provide efficient data management, storage, retrieval, and manipulation. Understanding database architecture is crucial for building robust, scalable, and efficient database systems.

Components of Database System Architecture
1. Database
- Definition: A structured collection of data stored and organized to be easily accessed, managed, and updated.
- Elements: Tables, indexes, views, stored procedures, triggers, etc.
2. Database Management System (DBMS)
- Definition: Software that interacts with end-users, applications, and the database itself to capture and analyze data.
- Functions:
- Data storage, retrieval, and update.
- User and access management.
- Backup and recovery management.
- Transaction management and concurrency control.
- Data integrity and security.
3. Hardware
- Definition: The physical devices used to store and process the database.
- Components:
- Servers: Host the DBMS and database.
- Storage Devices: Hard drives, SSDs, or cloud storage for data storage.
- Network: Provides connectivity for client-server architecture.
4. Software
- Definition: The set of programs and applications that facilitate interaction with the database.
- Components:
- Operating System: Manages hardware resources and provides a platform for DBMS.
- DBMS Software: Manages database operations.
- Application Software: Interfaces with the DBMS to perform specific business functions.
5. Users
- Definition: Individuals or applications interacting with the database.
- Types:
- Database Administrators (DBAs)
- Application Developers
- End Users (Casual, Parametric, and Power Users)
- Data Analysts and Scientists
6. Query Processor
- Definition: Component responsible for interpreting and executing database queries.
- Functions:
- Parsing: Analyzing the syntax of SQL queries.
- Optimization: Finding the most efficient way to execute queries.
- Execution: Running the queries on the database and returning results.
7. Transaction Manager
- Definition: Ensures that database transactions are processed reliably and adhere to ACID properties (Atomicity, Consistency, Isolation, Durability).
- Functions:
- Transaction Control: Managing begin, commit, and rollback operations.
- Concurrency Control: Ensuring multiple transactions can occur simultaneously without conflicts.
- Recovery: Restoring the database to a consistent state after failures.
8. Storage Manager
- Definition: Manages the storage and retrieval of data on physical storage devices.
- Functions:
- File Management: Organizing data files on disk.
- Buffer Management: Managing in-memory data storage for efficient access.
- Disk Space Management: Allocating and deallocating disk space for data storage.
Query Processor:
The query processor components include
· DDL interpreter, which interprets DDL statements and records the definitions in the data dictionary.
· DML compiler, which translates DML statements in a query language into an evaluation plan consisting
of low-level instructions that the query evaluation engine understands.
A query can usually be translated into any of a number of alternative evaluation plans that all give the same
result. The DML compiler also performs query optimization, that is, it picks the lowest cost evaluation plan
from among the alternatives.
Query evaluation engine, which executes low-level instructions generated by the DML compiler.
Storage Manager:
A storage manager is a program module that provides the interface between the lowlevel data stored in the
database and the application programs and queries submitted to the system. The storage manager is
responsible for the interaction with the file manager. The raw data are stored on the disk using the file system,
which is usually provided by a conventional operating system. The storage manager translates the various DML
Entity , Entity Sets
In database management, an entity is a distinct, identifiable object or thing that exists in the real world and can be represented in a database. Entities can be physical objects, like a person or a product, or more abstract concepts, like a company or a department.
Entity Sets are collections of similar types of entities. Each entity in an entity set has the same attributes but may have different values for those attributes. For example, if you have an entity set called Employees, each entity in this set represents an individual employee, and the attributes might include employee ID, name, and position.
1.Entity: An entity is a distinct, identifiable object or thing in a domain of interest, which can be uniquely represented in a database. For example, a single person or a specific product can be considered an entity.
2.Entity Set: An entity set is a collection of similar types of entities that share the same attributes. Each entity in the set represents a specific instance of the entity type. For example, an entity set named Employees would include all individual employee records in a company, with attributes such as employee ID, name, and position.
Entities can be classified into:
1.weak entity
2.Strong entity
Strong Entities: These entities can exist independently and have their own unique identifiers. For example, a Customer entity that has attributes like customer ID, name, and address is a strong entity.
Weak Entities: These entities cannot exist independently and rely on a strong entity for identification. They typically have a partial key and are identified by their relationship with a strong entity. For example, an Order entity might be a weak entity if it depends on a Customer entity for identification.
Relationship and Relationship sets
In database management, a relationship and a relationship set are used to define how entities interact with each other. Here’s what each term means:
- Relationship: A relationship represents an association between two or more entities. It defines how entities are related to each other and the nature of their interaction. For example, a
Works_Forrelationship might link theEmployeeentity to theDepartmententity, indicating which employees work in which departments. - Relationship Set: A relationship set is a collection of similar relationships of the same type. It encompasses all the instances of a particular relationship between entities. For example, if you have a
Works_Forrelationship, theWorks_Forrelationship set would include all individual instances of employees working in various departments.
To summarize:
- Relationship: An individual association between entities (e.g., an employee working in a specific department).
- Relationship Set: A collection of all such associations of the same type (e.g., all employee-department pairs in the company).
Keys in DBMS
1. Primary Key
- Definition: A primary key is a unique identifier for each record in a table. It ensures that each record can be uniquely identified.
- Example: In a
Userstable,UserIDcould be the primary key. For instance:
| UserID | Name | |
|---|---|---|
| 1 | Bhanu | bhanu@example.com |
| 2 | Alice | alice@example.com |
| 3 | Bob | bob@example.com |
UserID uniquely identifies each record.2. Foreign Key
- Definition: A foreign key is an attribute in one table that references the primary key of another table, establishing a relationship between the two tables.
- Example: Suppose we have an
Orderstable whereUserIDis a foreign key referencing theUserIDin theUserstable:
Users Table:
| UserID | Name | |
|---|---|---|
| 1 | Bhanu | bhanu@example.com |
| 2 | Alice | alice@example.com |
Orders Table:
| OrderID | UserID | OrderDate |
|---|---|---|
| 101 | 1 | 2024-08-01 |
| 102 | 2 | 2024-08-02 |
In this case, UserID in the Orders table is a foreign key that references UserID in the Users table.
3. Candidate Key
- Definition: A candidate key is a set of attributes that can uniquely identify a record in a table. Each candidate key can potentially be a primary key.
- Example: In a
Userstable, bothEmailandUserIDcould be candidate keys:
| UserID | Name | |
|---|---|---|
| 1 | Bhanu | bhanu@example.com |
| 2 | Alice | alice@example.com |
Here, both UserID and Email can uniquely identify each user. If UserID is chosen as the primary key, Email serves as an alternate key.
4. Alternate Key
- Definition: An alternate key is a candidate key that is not chosen as the primary key but still ensures uniqueness.
- Example: If
UserIDis the primary key in theUserstable, thenEmailserves as an alternate key. In the table:
| UserID | Name | |
|---|---|---|
| 1 | Bhanu | bhanu@example.com |
| 2 | Alice | alice@example.com |
Here, Email is an alternate key that also uniquely identifies each record.
5. Composite Key
- Definition: A composite key is a combination of two or more attributes that together uniquely identify a record in a table.
- Example: In a
CourseEnrollmentstable, a combination ofUserIDandCourseIDcould serve as a composite key:
Users Table:
| UserID | Name |
|---|---|
| 1 | Bhanu |
| 2 | Alice |
Courses Table:
| CourseID | CourseName |
|---|---|
| C101 | Math |
| C102 | Science |
CourseEnrollments Table:
| UserID | CourseID | EnrollmentDate |
|---|---|---|
| 1 | C101 | 2024-08-01 |
| 1 | C102 | 2024-08-02 |
| 2 | C101 | 2024-08-03 |
Here, the combination of UserID and CourseID uniquely identifies each enrollment record.
6. Super Key
- Definition: A super key is any set of attributes that uniquely identifies a record in a table. It may include additional attributes beyond those necessary for uniqueness.
- Example: In the
Userstable, a super key could be a combination ofUserID,Email, andName, thoughUserIDalone is sufficient:
| UserID | Name | |
|---|---|---|
| 1 | Bhanu | bhanu@example.com |
| 2 | Alice | alice@example.com |
Here, the combination of UserID, Email, and Name forms a super key, though UserID alone is a candidate key.
Map Cardinalities of a Relationship
Relationship cardinalities specify how many of each entity type is allowed. Relationships can have four possible
connectivities as given below.
- One to one (1:1) relationship
- One to many (1:N) relationship
- Many to one (M:1) relationship
- Many to many (M:N) relationship
The minimum and maximum values of this connectivity is called the cardinality of the relationship
1. One-to-One (1:1)
- Definition: A one-to-one relationship means that each instance of Entity A is associated with exactly one instance of Entity B,
2. One-to-Many
- Definition: An instance of Entity A can be associated with multiple instances of Entity B, but each instance of Entity B is associated with at most one instance of Entity A.
3. Many-to-One (N:1)
- Definition: Multiple instances of Entity A can be associated with a single instance of Entity B, but each instance of Entity B is associated with at most one instance of Entity A.

Many-to-Many (M)
- Definition: Instances of Entity A can be associated with multiple instances of Entity B, and instances of Entity B can be associated with multiple instances of Entity A.
.png)
Conclusion
The number of instances of one entity that can be connected to the number of instances of another object is specified by mapping cardinalities in a database schema, which explain how entities (tables) link to one another. This kind of interaction is essential for preserving data integrity and precisely simulating processes in the real world within a database. By expressing cardinalities as one-to-one, one-to-many, and many-to-many, mapping cardinalities aids in defining the guidelines for data interactions in database management systems (DBMSs).
Symbols used in ER model
1. Entity
- Symbol: A rectangle
- Description: Represents an object or thing in the real world that can be distinctly identified. Entities are often represented as boxes containing the entity’s name.
2. Attribute
- Symbol: An oval or ellipse
- Description: Represents a property or characteristic of an entity. Attributes are connected to their respective entity by a line.
3. Relationship
- Symbol: A diamond
- Description: Represents an association between two or more entities. Relationships describe how entities are related to each other.
4. Primary Key
- Symbol: Underlined attribute name
- Description: An attribute or set of attributes that uniquely identifies each instance of an entity.
5. Foreign Key
- Symbol: Attribute name with a reference line to another entity’s primary key
- Description: An attribute in one entity that refers to the primary key of another entity to establish a relationship.
6. Cardinality
- Symbol: Noted by lines with annotations or markings
- Description: Indicates the number of instances of one entity that can or must be associated with each instance of another entity. Common notations include 1:1, 1, and M.
7. Weak Entity
- Symbol: A double rectangle
- Description: Represents an entity that cannot be uniquely identified by its own attributes alone and relies on a strong entity and a partial key.
8. Multivalued Attribute
- Symbol: A double oval
- Description: Represents an attribute that can have multiple values for a single entity instance.

Entity Relationship models
Entity-Relationship (ER) models are used to visually represent the data and relationships within a database. They are a critical part of database design, helping to conceptualize how data elements relate to each other. Here’s an overview of the core components of ER models and their common types:

Entity
An Entity may be an object with a physical existence – a particular person, car, house, or employee – or it may be an object with a conceptual existence – a company, a job, or a university course.
For Example, A company may store the information of dependents (Parents, Children, Spouse) of an Employee. But the dependents can’t exist without the employee. So Dependent will be a Weak Entity Type and Employee will be Identifying Entity type for Dependent, which means it is Strong Entity Type.
A weak entity type is represented by a Double Rectangle. The participation of weak entity types is always total. The relationship between the weak entity type and its identifying strong entity type is called identifying relationship and it is represented by a double diamond.
For Example, A company may store the information of dependents (Parents, Children, Spouse) of an Employee. But the dependents can’t exist without the employee. So Dependent will be a Weak Entity Type and Employee will be Identifying Entity type for Dependent, which means it is Strong Entity Type.
A weak entity type is represented by a Double Rectangle. The participation of weak entity types is always total. The relationship between the weak entity type and its identifying strong entity type is called identifying relationship and it is represented by a double diamond.

Strong Entity and Weak Entity
Attributes
Attributes are the properties that define the entity type. For example, Roll_No, Name, DOB, Age, Address, and Mobile_No are the attributes that define entity type Student. In ER diagram, the attribute is represented by an oval.

Attribute
1. Key Attribute
The attribute which uniquely identifies each entity in the entity set is called the key attribute. For example, Roll_No will be unique for each student. In ER diagram, the key attribute is represented by an oval with underlying lines.

Key Attribute
2. Composite Attribute
An attribute composed of many other attributes is called a composite attribute. For example, the Address attribute of the student Entity type consists of Street, City, State, and Country. In ER diagram, the composite attribute is represented by an oval comprising of ovals.
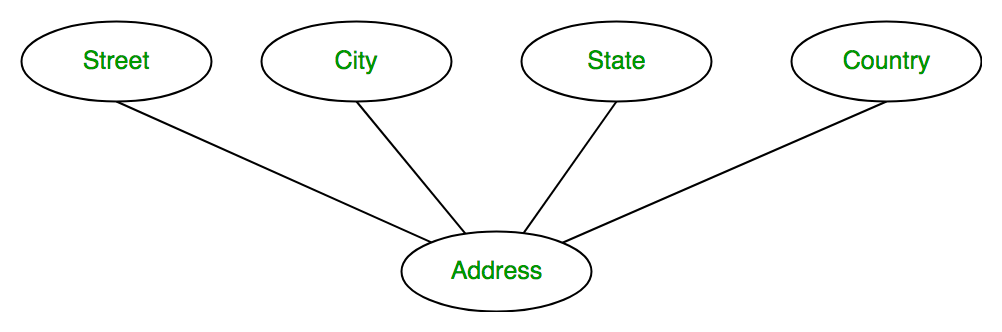
Composite Attribute
3. Multivalued Attribute
An attribute consisting of more than one value for a given entity. For example, Phone_No (can be more than one for a given student). In ER diagram, a multivalued attribute is represented by a double oval.

Multivalued Attribute
4. Derived Attribute
An attribute that can be derived from other attributes of the entity type is known as a derived attribute. e.g.; Age (can be derived from DOB). In ER diagram, the derived attribute is represented by a dashed oval.

Derived Attribute
The Complete Entity Type Student with its Attributes can be represented as:

Entity and Attributes
Relationship Type and Relationship Set
A Relationship Type represents the association between entity types. For example, ‘Enrolled in’ is a relationship type that exists between entity type Student and Course. In ER diagram, the relationship type is represented by a diamond and connecting the entities with lines.

Entity-Relationship Set
A set of relationships of the same type is known as a relationship set. The following relationship set depicts S1 as enrolled in C2, S2 as enrolled in C1, and S3 as registered in C3.

Relationship Set
Degree of a Relationship Set
The number of different entity sets participating in a relationship set is called the degree of a relationship set.
1. Unary Relationship: When there is only ONE entity set participating in a relation, the relationship is called a unary relationship. For example, one person is married to only one person.

Unary Relationship
2. Binary Relationship: When there are TWO entities set participating in a relationship, the relationship is called a binary relationship. For example, a Student is enrolled in a Course.
Binary Relationship
3. Ternary Relationship: When there are n entities set participating in a relation, the relationship is called an n-ary relationship.
Cardinality
The number of times an entity of an entity set participates in a relationship set is known as cardinality. Cardinality can be of different types:
1. One-to-One: When each entity in each entity set can take part only once in the relationship, the cardinality is one-to-one. Let us assume that a male can marry one female and a female can marry one male. So the relationship will be one-to-one.
the total number of tables that can be used in this is 2.

one to one cardinality
Using Sets, it can be represented as:

Set Representation of One-to-One
2. One-to-Many: In one-to-many mapping as well where each entity can be related to more than one entity and the total number of tables that can be used in this is 2. Let us assume that one surgeon department can accommodate many doctors. So the Cardinality will be 1 to M. It means one department has many Doctors.
total number of tables that can used is 3.

one to many cardinality
Using sets, one-to-many cardinality can be represented as:

Set Representation of One-to-Many
3. Many-to-One: When entities in one entity set can take part only once in the relationship set and entities in other entity sets can take part more than once in the relationship set, cardinality is many to one. Let us assume that a student can take only one course but one course can be taken by many students. So the cardinality will be n to 1. It means that for one course there can be n students but for one student, there will be only one course.
The total number of tables that can be used in this is 3.
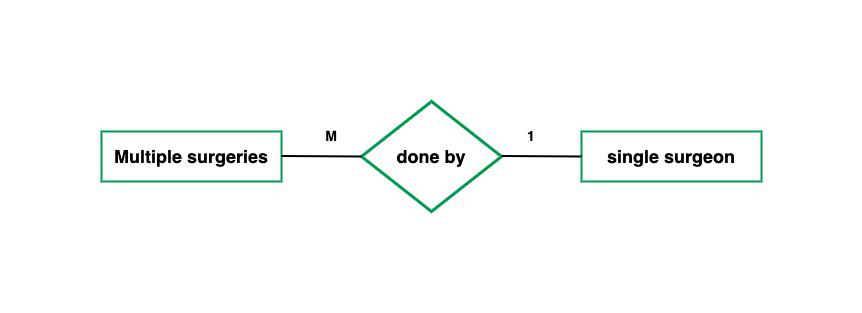
many to one cardinality
Using Sets, it can be represented as:

Set Representation of Many-to-One
In this case, each student is taking only 1 course but 1 course has been taken by many students.
4. Many-to-Many: When entities in all entity sets can take part more than once in the relationship cardinality is many to many. Let us assume that a student can take more than one course and one course can be taken by many students. So the relationship will be many to many.
the total number of tables that can be used in this is 3.

many to many cardinality
Using Sets, it can be represented as:

Many-to-Many Set Representation
In this example, student S1 is enrolled in C1 and C3 and Course C3 is enrolled by S1, S3, and S4. So it is many-to-many relationships.
Participation Constraint
Participation Constraint is applied to the entity participating in the relationship set.
1. Total Participation – Each entity in the entity set must participate in the relationship. If each student must enroll in a course, the participation of students will be total. Total participation is shown by a double line in the ER diagram.
2. Partial Participation – The entity in the entity set may or may NOT participate in the relationship. If some courses are not enrolled by any of the students, the participation in the course will be partial.
The diagram depicts the ‘Enrolled in’ relationship set with Student Entity set having total participation and Course Entity set having partial participation.

Total Participation and Partial Participation
Using Set, it can be represented as,

Set representation of Total Participation and Partial Participation
Every student in the Student Entity set participates in a relationship but there exists a course C4 that is not taking part in the relationship.
Generalization, Specialization and Aggregation in ER Model
Using the ER model for bigger data creates a lot of complexity while designing a database model, So in order to minimize the complexity Generalization, Specialization, and Aggregation were introduced in the ER model and these were used for data abstraction in which an abstraction mechanism is used to hide details of a set of objects. Some of the terms were added to the Enhanced ER Model, where some new concepts were added. These new concepts are:
- Generalization
- Specialization
- Aggregation
Generalization
Generalization is the process of extracting common properties from a set of entities and creating a generalized entity from it. It is a bottom-up approach in which two or more entities can be generalized to a higher-level entity if they have some attributes in common. For Example, STUDENT and FACULTY can be generalized to a higher-level entity called PERSON as shown in Figure 1. In this case, common attributes like P_NAME, and P_ADD become part of a higher entity (PERSON), and specialized attributes like S_FEE become part of a specialized entity (STUDENT).
Generalization is also called as ‘ Bottom-up approach”.

Specialization
In specialization, an entity is divided into sub-entities based on its characteristics. It is a top-down approach where the higher-level entity is specialized into two or more lower-level entities. For Example, an EMPLOYEE entity in an Employee management system can be specialized into DEVELOPER, TESTER, etc. as shown in Figure 2. In this case, common attributes like E_NAME, E_SAL, etc. become part of a higher entity (EMPLOYEE), and specialized attributes like TES_TYPE become part of a specialized entity (TESTER).
Specialization is also called as ” Top-Down approch”.

Aggregation
An ER diagram is not capable of representing the relationship between an entity and a relationship which may be required in some scenarios. In those cases, a relationship with its corresponding entities is aggregated into a higher-level entity. Aggregation is an abstraction through which we can represent relationships as higher-level entity sets.
For Example, an Employee working on a project may require some machinery. So, REQUIRE relationship is needed between the relationship WORKS_FOR and entity MACHINERY. Using aggregation, WORKS_FOR relationship with its entities EMPLOYEE and PROJECT is aggregated into a single entity and relationship REQUIRE is created between the aggregated entity and MACHINERY.

Functional Dependencies and ,Normalization 1 NF,2 NF and 3NF
Functional Dependencies
Functional Dependencies (FDs) are a key concept in database design that describe the relationship between attributes in a relational database. A functional dependency occurs when one attribute or a group of attributes uniquely determines another attribute or a group of attributes.
- Notation: If attribute
Afunctionally determines attributeB, it is denoted asA → B. - Example: If in a
Studenttable,StudentIDuniquely determinesNameandEmail, thenStudentID → Name, Email.
Normalization
Normalization is a process in database design that organizes attributes and tables to minimize redundancy and dependency. It involves decomposing tables into smaller, more manageable tables while preserving data integrity. Normalization is achieved through a series of steps called normal forms (1NF, 2NF, 3NF, etc.).
1. First Normal Form (1NF)
Definition: A table is in 1NF if it contains only atomic (indivisible) values and each column contains only a single value of a specific type.
- Requirement:
- Each column must contain atomic values.
- Each column must contain values of the same type.
- Each column must have a unique name.
- The order in which data is stored does not matter.
Example:
Non-1NF Table:
| StudentID | Name | Courses |
|---|---|---|
| 1 | Bhanu | Math, Science |
| 2 | Alice | English, History |
1NF Table:
| StudentID | Name | Course |
|---|---|---|
| 1 | Bhanu | Math |
| 1 | Bhanu | Science |
| 2 | Alice | English |
| 2 | Alice | History |
2. Second Normal Form (2NF)
Definition: A table is in 2NF if it is in 1NF and all non-key attributes are fully functionally dependent on the entire primary key. This means that there should be no partial dependency of any column on a part of a composite key.
- Requirement:
- The table must be in 1NF.
- All non-key attributes must be fully functionally dependent on the entire primary key.
Example:
Non-2NF Table:
| StudentID | CourseID | Instructor | InstructorPhone |
|---|---|---|---|
| 1 | C101 | Prof. A | 123-456-7890 |
| 1 | C102 | Prof. B | 987-654-3210 |
| 2 | C101 | Prof. A | 123-456-7890 |
1NF and 2NF Tables:
Table 1: StudentCourse
| StudentID | CourseID |
|---|---|
| 1 | C101 |
| 1 | C102 |
| 2 | C101 |
Table 2: CourseInstructor
| CourseID | Instructor | InstructorPhone |
|---|---|---|
| C101 | Prof. A | 123-456-7890 |
| C102 | Prof. B | 987-654-3210 |
3. Third Normal Form (3NF)
Definition: A table is in 3NF if it is in 2NF and there are no transitive dependencies. This means that non-key attributes must not depend on other non-key attributes.
- Requirement:
- The table must be in 2NF.
- There should be no transitive dependencies; non-key attributes should depend only on the primary key.
Example:
Non-3NF Table:
| StudentID | CourseID | Instructor | InstructorPhone | InstructorOffice |
|---|---|---|---|---|
| 1 | C101 | Prof. A | 123-456-7890 | Room 101 |
| 1 | C102 | Prof. B | 987-654-3210 | Room 202 |
| 2 | C101 | Prof. A | 123-456-7890 | Room 101 |
3NF Tables:
Table 1: StudentCourse
| StudentID | CourseID |
|---|---|
| 1 | C101 |
| 1 | C102 |
| 2 | C101 |
Table 2: CourseInstructor
| CourseID | Instructor | InstructorPhone |
|---|---|---|
| C101 | Prof. A | 123-456-7890 |
| C102 | Prof. B | 987-654-3210 |
Table 3: Instructor
| Instructor | InstructorPhone | InstructorOffice |
|---|---|---|
| Prof. A | 123-456-7890 | Room 101 |
| Prof. B | 987-654-3210 | Room 202 |
In this example, the transitive dependency of InstructorOffice on InstructorPhone is removed by separating Instructor into its own table.
Summary
- 1NF: Ensures atomicity of values.
- 2NF: Ensures all non-key attributes are fully dependent on the entire primary key, eliminating partial dependencies.
- 3NF: Ensures no transitive dependencies, meaning non-key attributes depend only on the primary key.
Normalization helps to design efficient, consistent, and scalable database schemas by reducing redundancy and improving data integrity.
EF.CODD’s Rules for RDBMS
Edgar F. Codd, the pioneer of the relational database model, proposed a set of rules that define what constitutes a true relational database management system (RDBMS). These rules, known as Codd’s Twelve Rules, were designed to ensure that a database system adheres to the principles of the relational model and provides the expected functionality. Here’s a summary of each rule:
Rule 1: Information Rule
- Definition: All information in a relational database is represented explicitly at the logical level in tables.
- Explanation: The relational model dictates that all data must be stored in a structured format using tables (or relations). Each table represents an entity and contains rows (tuples) and columns (attributes). This ensures that every piece of information is represented consistently and uniformly within the database schema. The use of tables allows for clear organization and retrieval of data.
Rule 2: Guaranteed Access Rule
- Definition: All data must be accessible without ambiguity, and it should be retrievable using a combination of table names, primary keys, and column names.
- Explanation: This rule ensures that every piece of data in the database can be accessed and retrieved using straightforward methods. Accessing data should involve specifying the table name, the primary key (if applicable), and the column name. This rule eliminates ambiguity in data retrieval and ensures that data can be located easily.
Rule 3: Systematic Treatment of Null Values
- Definition: Null values (representing missing or inapplicable information) must be uniformly treated.
- Explanation: Null values represent data that is missing, undefined, or not applicable. The relational model mandates a consistent way to handle null values across the database. This uniform treatment helps avoid confusion and ensures that missing data is properly accounted for and handled in a predictable manner.
Rule 4: Dynamic On-Line Catalog Based on the Relational Model
- Definition: The database’s catalog (metadata) must be available and accessible in the same way as regular data. The catalog itself must be stored as tables in the database.
- Explanation: Metadata about the database schema, such as table definitions, column types, and constraints, should be stored in tables within the database. This allows for the metadata to be accessed and queried using the same relational model, providing a consistent and unified view of both data and metadata.
Rule 5: Comprehensive Data Sublanguage Rule
- Definition: The system must support a comprehensive language that allows for data definition, manipulation, and transaction management.
- Explanation: The relational database system should support a robust and comprehensive language (such as SQL) that can handle all aspects of database operations, including defining data structures, manipulating data, and managing transactions. This ensures that users have a single, powerful language to work with for all database tasks.
Rule 6: View Updating Rule
- Definition: Any view that is theoretically updatable must be updatable through the same mechanism that is used to update base tables.
- Explanation: Views are virtual tables derived from base tables. If a view is defined in a way that allows updates, those updates should be reflected in the underlying base tables. This rule ensures consistency and allows users to interact with data through views while maintaining the integrity of the base tables.
Rule 7: High-Level Insert, Update, and Delete
- Definition: The system must support set-based operations (i.e., operations on sets of rows) rather than just single-row operations.
- Explanation: The relational model should allow for operations to be performed on sets of rows at a time, not just on individual rows. This high-level approach enables more efficient and flexible data manipulation, allowing users to perform batch operations and handle large volumes of data with ease.
Rule 8: Physical Data Independence
- Definition: Changes to the physical storage of data should not affect the way data is accessed or manipulated at the logical level.
- Explanation: The database system should be designed such that changes to how data is physically stored (e.g., on disk) do not impact how users interact with data at the logical level (e.g., through queries). This separation helps ensure that database applications remain unaffected by changes in storage technology or optimization.
Rule 9: Logical Data Independence
- Definition: Changes to the logical structure of the database (e.g., adding new fields) should not require changes to the applications that use the database.
- Explanation: The database schema should be designed so that modifications to the logical structure (e.g., adding or removing columns) do not necessitate changes in the applications that access the database. This rule supports flexibility and adaptability in the database design.
Rule 10: Integrity Independence
- Definition: Integrity constraints must be specified separately from application programs and should be stored in the catalog.
- Explanation: Constraints that ensure data integrity (e.g., primary keys, foreign keys) should be defined and managed within the database schema itself, rather than being embedded in application code. This centralization of constraints helps maintain data consistency and enforces rules uniformly.
Rule 11: Distribution Independence
- Definition: The database should be able to operate as if it were not distributed, even if it is distributed across multiple locations.
- Explanation: The relational database system should abstract the details of data distribution across multiple locations so that users and applications interact with the database as if it were a single, unified system. This rule simplifies the user experience and application development by hiding the complexity of data distribution.
Rule 12: Non-Subversion Rule
- Definition: If the system provides a low-level (e.g., file system) interface, it must not bypass the integrity rules and constraints enforced by the high-level relational model.
- Explanation: Even if a database system offers low-level access methods (e.g., direct file manipulation), these methods should not allow users to bypass or violate the integrity constraints defined by the relational model. This rule ensures that data integrity is preserved regardless of the access method used.
These rules provide a framework for evaluating whether a database management system adheres to the principles of the relational model, ensuring it meets the standards for relational database functionality and integrity.